CS73N Meeting 10 Notes: Search Engines 13 Feb 2003
Browsers
Enabled the web for broad usage (Mosaic at UIUC, then Netscape, various competitors -- often adding new source formats, plug-ins for generality, then MS Internet Explorer.)
- Translate HTML and linked material to Human-readable presentations
- Translate XML via a specified XSL, and linked material to Human-readable presentations
Size of the Web
"A year 2000 study by Inktomi and NEC Research Institute show that there are at least one billion unique indexable Web pages on the internet. The details are pretty interesting; for example, Apache dominates the server market." (17Jan2000)
The actual statistics are at http://www.inktomi.com/webmap/.
Re 1,000,000,000 documents, from a 1964 book about a near-infinite library that contained all the 500 page books that could be generated by permuting the alphabet:
"The certitude that any book exists on the shelves of the library first led to elation, but soon the realization that it was unlikely to be found converted the feelings to a great depression. [Luis Borges: The Infinite Library]"
Is getting more better ?
------------------------
Search Engines
All Search engines must carry out in some way the following tasks
- Collect web pages
- by human submission, evaluation, selection
- by crawling: going from one page to another following embedded hyperlinks to their leaves. (where to start?)
- Not well covered: pages that are dynamically created from databases, often by filling in forms: the hidden web
- link them so they can be searched
- create indexes
- categorize them according to some ontology
- rank them
- by frequency of term -- normalized
- by relative frequency of term wrt. all documents
- by value of references (Google)
- by human assessment
- by frequency of use (requires dynamic access as Doubleclick)
- These techniques interact with each other, some examples:
Search Techniques
[extract from Gio Wiederhold: Trends for the Information Technology Industry; Stanford University, April 1999.]
There is a wide variety of search techniques available. They are rarely clearly explained to the customers, perhaps because a better understanding might cause customers to move to other searches. Since the techniques differ, results will differ as well, but comparisons are typically based in recall rather than on precision. Getting more references always improves recall, but assessing precision formally requires an analysis of relevance, and knowing what has been missed, which is an impossible task given the size and dynamics of the web.
Potentially more relevant results can be obtained by intersecting the results from a variety of search techniques, although precision is then likely to suffer further.
We briefly describe below the principal techniques used by some well-known search engines; they can be experienced by invoking www.name.com. This summary can provide hints for further improvements in the tools.
Yahoo
catalogues useful web sites and organizes them as a hierarchical list of web-addresses. By searching down the hierarchy the field is narrowed, although at each bottom leaf many entries remain, which can then be further narrowed by using keywords. Yahoo employs now a staff of about 200 people, each focusing on some area, who filter web pages that are submitted for review or located directly, and categorizes those pages into the existing classification. Some of the categories are dynamic, as recent events and entertainment, and aggregate information when a search is requested.
Note that Yahoo used to use InkToMe as its search engine provider, but switched in 2001 to Google.
Alta Vista
automates the process, by surfing the web, creating indexes for terms extracted from the pages, and then using high-powered computers to report matches to the users. Except for limits due to access barriers, the volume of possibly relevant references is impressive. However, the result is typically quite poor in precision. Since the entire web is too large to be scanned frequently, references might be out of date, and when content has changed slightly, redundant references are presented. Context is ignored, so that when seeking, say, a song title incorporating the name of a town, information about the town is returned as well.
Excite
combines some of the features, and also keeps track of queries. If prior queries exist, those results are given priority. Searches are also broadened by using the ontology service of Wordnet [Miller:93]. The underlying notion is that customers can be classified, and that customers in the same class will share interests. However, asking similar queries and relating them to individual users is a limited notion, and leads only sometimes to significantly better results. Collecting personal information raises questions of privacy protection.
Firefly
provides customer control over their profiles. Individuals submit information that will encourage businesses to provide them with information they want [Maes:94]. However, that information is aggregated to create clusters of similar consumers, protecting individual privacy. Business can use the system to forward information and advertisements that are appropriate to that cluster. There is a simplification of matching a person to a single customer role. Many persons have multiple roles. At times they may be a professional customer, seeking business information, and at other times they may pursue their sports hobby, and subsequently they may plan a vacation for their family. Unless these customer roles can be distinguished, the clustering of individuals is greatly weakened.
Alexa
collects not only references, but also the webpages themselves. This allows Alexa to present information that has been deleted from the source files. Ancillary information about web pages is also provided, as the author organization, the extent and the number of links referring to this page. Such information helps the customer judge the quality of information on the page. Presenting web pages that have been deleted provides an archival service, although the content may be invalid. The creators of such webpages can request Alexa to stop showing them, for instance if the page contained serious errors or was libelous. Since the inverted links are made available one can also go to referencing sites.
ranks the importance of web pages according to the total importance of web pages that refer to it. This definition is circular, and Googleperforms the required iterative computation to estimate the scaled rank of all pages relative to each other. The effect is that often highly relevant information is returned first. It also looks for all matches to all terms, which reduces the volume greatly, but may miss relevant pages [PageB:98].
Junglee
provides integration over diverse sources. By inspecting sources, their formats are discerned, and the information is placed into tables that then can be very effectively indexed. This technology is suitable for fields where there is sufficient demand, so that the customer needs can be understood and served, as advertisements for jobs, and searches for merchandise. later time by the same or a related application. For instance, a search for some movie, recorded in a cookie, can trigger an advertisement for a similar movie later. The use of cookies moves the storage of user-specific information to the user Accessing and parsing multiple sources allows, for instance, price comparisons to be produced. Vendors who wish to differentiate themselves based on the quality of their products (see Section 2.2.3) may dislike such comparisons.
Cookies
is not an independent search engine, but a device used by many engines and applications to track users of use, the `freshness rejecting of cookies and applications that generate cookies.
This list of techniques can be arbitrarily extended. New ideas in improving the relevance and precision of searches are still developing [Hearst:97]. There are, however, limits to general tools. Three important additional factors conspire against generality, and will require a new level of processing if searching tools are to become effective.
Problems with Searching
- Getting all that is relevant = Recall -- Query formulation with alternate terms, paths
- Getting only what is relevant = Precision -- Word meanings differ in context -- intersect multiple terms
- Getting duplicates (report, paper, book chapter, .. on distinct paths) -- SCAM project
- Integration from multiple contexts -- mismatched terms
Measures of performance
The customer's objective when searching is
- Finding all relevant information: Perfect Recall, as long as it does not overload them.
- not receiving any irrelevant stuff: High precision
These two objectives conflict with each other.
Perfect recall can be obtained by giving you all of the web!
But now precision is minimal. A browser should use methods that maximize precision (by ranking results).
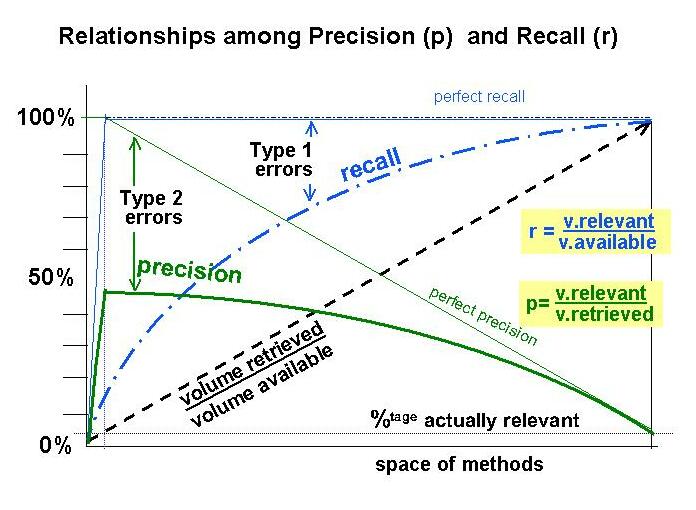
The information density decreases towards the right. The best methods are on the left.
Type 1 errors measure material not retrieved that should have been
Type 2 errors measure material retrieved that should not have been
Note that in the web the amount of material wanted (the thin box on the left), is infinitesimal versus the stuff that is available.