Trends for the Information Technology Industry
Gio Wiederhold
Stanford University
April 1999
This report was prepared under sponsorship of the Japan External Trade Organization (JETRO),
25 Pine Street, suite 1700, San Francisco CA 94104.
Updated 2 May, 21Sep., 1, 11 Oct. 1999.
1. Analysis Approach
We see two factors contributing to the explosive growth in the information industry. The first one is the push and excitement generated by the constant stream of new devices and choices. At the same time, consumers, both private and businesses, are under pressure to be effective with their time and other resources. While these factors can combine to create synergy in demand for products of industry supplying information technology products, they can also create delays and barriers when technology does not provide devices and software that serve the consumer appropriately. We will investigate the two factors below.
1.1 Technology Push
Rapidly improving semiconductor manufacturing capabilities produce products with performance improvements that render computing equipment obtained obsolete within one or two years. Continuing deployment of communication gear broadens access capabilities [AAAS:99]. Distance is becoming a minor factor in communication cost, since the cost of the `last mile’, the connection to the home or business is not decreasing as fast as longer distance communications [Cairncross:97]. Performance of computing and communication hardware increasing at virtually constant cost enables access to complex multi-media sources [Hamilton:99].
1.2 Consumer Pull
A consumer may perceive that competition demands new capabilities. When friends and colleagues upgrade their equipment it is hard not to follow, whether the reason is real or emotional. Even minor requirements can force equipment purchases if software for older version of computer hardware is not maintained or created.
The combination of the two trends has caused a rapid rise in the customer base for information technology [OCLC:99]. There are few people in the world who are not at least aware of computing, and in many countries computing technology is an integral part of nearly every workplace [Dyson:97]. This change has been rapid. Personal computers became available in 1974, and the advent of VisiCalc in 1979 transformed personal computers from an intellectual curiosity to a business tool. Databases, formalized from Codd’s relational model in 1970 [Codd:70], appeared as practical tools around 1985 and initiated the concept of services provided by specialists who were distinct from the application programmers.
It has been estimated that in the US 7.4 million people are performing work directly related to the computer industry, $750 billion business, and responsible for 1/3 of U.S. economic growth [PTAC:98]. A large fraction of these industrial totals is due to information technology, but the number of customers for information technology is proportionally even greater. The Internet became available to business and private users in 1983, after a long gestation in the military and associated academic centers. Although some experts question the long-term benefits, the consensus is that use of the Internet will continue to grow [Stoll:96]. The facilities that now comprise the World-Wide Web became available through the Mosaic software in 1993. Today about 159 million people are online, 265 million PCs are projected to be in operation by 2000 and by 2003 the number of people on-line is expected to be 510 million [Hof:99].
1.3 Focus of this Report
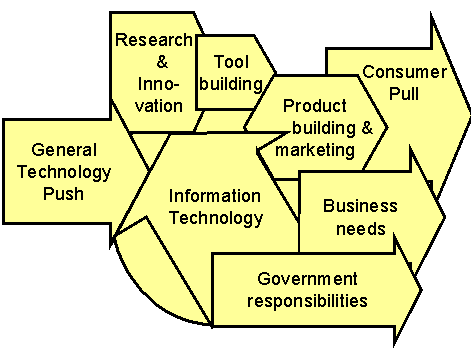
We will briefly indicate current factors and problems that will affect future system development. References will provide some more background, but current status, capabilities, and problems are well understood. We avoid details of technology, since these are also well understood and publicized, although the rate of progress is always open to question. However, our technological capabilities are likely to be able to support requirements that customers place on information systems, if the means to satisfy the requirements are clear. Figure 1 shows the influences we consider.
Section 2 investigates the drivers for change, focusing on societal aspects, and Section 3 complements this view by focusing on individual expectations. Section 4 estimates the reaction of business and industry to the needs expressed and Section 5 extrapolates that need to the scale of governments and multi-national organizations.
Section 6 provides a modest basis for some of the forecasts, which is mainly placed into a market reaction context. In Section 7 we move to more specific drivers for innovation in information systems.
The most important section of this report is then Section 8: Research needs. This section lists some specific issues and supporting technologies that should be resolved to make modern information systems responsive to needs by individual, business, and governmental customers. We proceed in Section 9 to technology transfer methodologies that are likely to be effective. After a brief conclusion we provide references, partially to high level studies and summaries, and some specific research that I am familiar with.
Figure 1. Influences on progress in information technology.
2. Societal and Technological Situations Driving Change
Computer and information technology has become sufficiently pervasive that they have changed societal interactions, especially in industrial nations. However, the technology is also becoming affordable in developing countries, and here the societal changes will be even greater.
Areas that will be affected greatly in the near future (less than 10 years) are libraries, selection of merchandise by individuals and businesses, and personal entertainment. Areas that also will undergo significant, although more gradual changes are education, governmental planning, manufacturing, healthcare services, etc. The actual speed of adoption of new technologies is hard to estimate, since traditionally adoption took about 12 years, as seen in examples listed above. Adoption is more rapid, of course, when the innovations are incremental, and do not replace established services. It is assumed now that the rate of adoption of change is increasing, and that clocks run on Internet time, i.e., at 6-month cycles [HafnerL:96]. When we are dealing with humans as well as with technology some compromise is likely [Stefik:96]. To what extent Internet time will continue to run as rapidly as it has in the recent past is unclear, and the interaction of human factors and established services is hard to deconvolute. In all new areas the easier problems are addressed initially, but in time difficult subtopics emerge, which take longer to resolve [Cuthbert:99].
Sections 2.1 to 2.4 we discuss four specific areas in some depth, to provide an understanding of a range of needs for information technology in the future. Since nearly all human enterprises are now affected by information technology it is impossible to be comprehensive.
2.1 Libraries
Libraries, being the traditional repository for information, are the most obvious target for replacement by information technology. The effect will be different in various segments of the library enterprise: libraries for intellectual entertainment, libraries for general education, libraries for scientific and technical topics, and libraries as a social meeting place in a community. The use of libraries for scientific and technical reference is already being replaced by digital libraries, reducing the customer base of traditional libraries and the publishers that supply those libraries [RamakrishnanMSW:95]. Although the number of people active in science is increasing the decrease of the customer base has initiated a fatal cycle, namely increases in prices of paper scientific journals, leading to a further reduction in the customer base, and so on.
At the same time digital libraries have not yet taken on the full role served by scientific publishers, scientific libraries, and librarians [Lesk:97]. Services provided here include selection of manuscripts submitted by authors for quality and upgrading of content after selection, provided by editors and specialist referees. Published papers will be indexed using keywords and controlled vocabularies [Cimino:96]. New works will be shipped to reviewers, who then will write abstracts that help potential readers identify relevant new works. Librarians will select, acquire, and shelf publications in areas of interest to their community. Significant arrivals will be placed on recent acquisition shelves to help customers find current material, and the shelves themselves are ranged so that physically neighboring books are likely to be of interest to a browser.
The traditional publication process has also many weaknesses. Involving the many intermediaries takes time, and typically several years pass between the time when the author has completed the initial manuscript before it is available in the local library. When a field changes rapidly the work may be obsolescent when it appears. Sound and video media cannot be easily incorporated, and even color images are costly to include. Work advocating truly novel concepts is easily rejected by referees that have an established point-of-view. In practice, only a few books are truly successful and warrant multiple printing runs. Most scientific papers have very few readers. Since most scientists are competent in using computers, they are relying increasingly on technology for their access to information. However, problems due to the current trend of disintermediation abound, and new intermediate services are required to regain the quality of the traditional processes, as discussed in Section 8.3.
Libraries in popular areas will follow these trends as well. While traditional publication will not be replaced where material has a long lifetime – say, classical books – or high-volume publications – say, primary school textbooks –, ancillary documents used for indexing, cross-referencing, background, or reference material will move to electronic services as well. As scientific and reference material moves to electronic bases, the traditional library services will lose some of their justification and income. Loss of revenue makes it likely that even services that remain valuable in a traditional setting will no longer be supported [Simons:98].
2.2 Electronic Commerce
Electronic commerce, the purchasing of merchandise and services, is a small, but rapidly increasing fraction of traditional commerce. Benefits for vendors are reductions in costs of having sales outlets, reduction of inventory, and easier scheduling of personnel since the workload can be distributed evenly over the working day. Benefits for the consumer are avoiding hassles of shopping, a wider selection of merchandise than can be found locally, and, if the vendors share their cost reductions, lower prices [ChoiSW:97]. Where merchandise can include many options, as personal computers, an ability to assemble the goods to order is beneficial for vendors and for clients.
Lost in most electronic interactions are an ability to personally inspect the merchandise, an ability to negotiate for special conditions, and an ability to have adjustment made after delivery. Some of the cost advantages can be lost due to increased shipping costs, since now merchandise is shipped piecemeal from the vendor.
2.2.1 Items for Electronic Commerce Electronic commerce is most effective for `fungible’ merchandise, i.e., items where one instance is identical to another, as books, CDs, and less for unique and valuable items, as works of art or used cars. In between these two types of goods is a large gap, which will gradually be bridged as electronic commerce becomes accepted. Even now we have auctions on the Internet, where participants bid on unique objects of moderate value [RodriguezEa:98].
While information services can be delivered over the Internet, most other services involve contact with people, as babysitters, personal trainers, healthcare, etc. There are many examples where goods and services are intertwined, as when going to a restaurant or traveling to a resort. Although the focus may be on the tangible object in such transactions, say the type of food in a restaurant, a majority of the cost and pleasure of eating out is actually in the interaction with the people providing the service. For services obtaining information prior to commitment, is the value-added by information technology.
2.2.2 Trust When dealing with tangible goods or services, the client has to have confidence that they will be delivered as promised, functional, and of the expected quality [Stefik:97]. Typically the supplier will provide a guarantee for the merchandise and the services, but there still has to be trust, that the guarantee will be honored. For well-known suppliers, that have already a quality image, converting the resulting trust is mainly an issue of honest advertising and responsive operations. A company as Hewlett-Packard has done well by leveraging its professional reputation into the consumer market for personal computers. As it actually moves to mainly distributing commodity computers it remains to be seen how long the distinction will be valued.
New enterprises will have a more difficult time in building trust. For merchandise that is of modest cost the customers may take the risk, especially if there is a valuable benefit, as price or selection. Risks are mitigated by consulting intermediary information: friends, restaurant guides, travel literature, consumer reports, etc. [ShardanandM:93]. These intermediaries themselves must develop trust, and may do so by associating themselves with existing, reputable organizations or publications. An estimate is that by the year 2002 twenty nice percent of E-commerce transactions will involve intermediaries [Hof:99].
Aspects of merchandise specifications to be trusted are delivery, functionality, and quality, as mentioned above. The first two can be objectively measured, and hence conformance to specifications and their guarantees is manageable. Quality is a more difficult issue.
2.2.3. Quality Mediation Reporting quality is a major service that expert intermediaries can provide. The sources of merchandise and services can be trusted to report sizes, functions, and costs. A failure to deliver as promised is easy to determine after the fact, but may lead to much higher costs than the price of a critical item, as discussed in Section 7.5.4.
Intermediaries are most effective if they understand the quality metrics in a particular domain, say restaurants, or even particular to Chinese restaurants, as dependence on MSG. Experts exist for most domains of interest to consumers. Today their products are found in advice columns in magazines and specialized newsletters. However, the printed advice is often out-of-date, and often not easily accessed when needed. Assuring that the fish in a restaurant is fresh requires frequent monitoring. Moving such services to the Internet would mitigate the difficulties of remaining up-to-date and enhance the value of the information.
Some sources that might be useful for assessing quality do not release their information freely. Examples are professional societies, as those for lawyers, physicians, and hospitals. Since these services are costly, but used only occasionally, customers have shown great interest in such data. Arguments for restricting the release of such information include the chance of misinterpretation, protection of privacy, and the existence of errors. Medical records, for instance, are often incomplete and replete with jargon [W:97H]. Responsible mediating services can mitigate those problems, but the service would have to be trusted by the sources as well as by the customers [Sweeney:97]. The world is moving towards more openness, so that it may be wiser for the sources to cooperate than to have reporting services that operate in an adverse relationship with them.
Establishing such mediating services as viable businesses has not been easy. While the hardware is affordable and many components of the needed software are available, assembling the pieces into a reliable whole is beyond the competence of most domain experts [W:98P]. Requiring computer expertise from domain experts decreases the availability of resources or forces them to engage costly consultants. A major uncertainty in setting up such services as a business is in which payment option to choose.
2.2.4 Paying How to pay for items in electronic commerce is the major open issue. A variety of models exist. Some of them are only applicable to information services, others include payment assurance for tangible goods to be delivered to the customer.
We will briefly list here alternatives seen or contemplated, focusing on the intermediary information services, although many schemes apply for direct purchase reimbursement as well [LynchL:96]. A full analysis of electronic payment schemes is beyond the scope of this report; our point here is that information technology tools must be flexible enough to accommodate several of them at the same time and all of them at some time.
1) The referred supplier pays the mediator for each actual purchase made by a customer. This approach assumes that there is a clear path from the mediated information provided to the eventual purchase. Today amazon.com provides such a service to specialist selection services [PapowsPM:98] [Amazon:99]. In settings where the actual purchases occur later, and can be assigned to a variety of information sources, the audit trail needed to justify payment may be hard to follow.
2) The referred service pays for each reference made to its site, whether it leads to a purchase or not. This approach assumes that the benefits for vendors, as airlines, restaurants, etc., are high enough that the mediator can get paid a small amount for each specific reference. However, in that case suspicions of bias are likely, whether justified or not.
3) The information provided by the mediating service is adjoined with advertisements directed towards the customer. This approach is prevalent today, and shows the importance of advertising in modern commerce. Here the cost to the customer is annoyance and distraction. A suspicion of bias will also arise.
4) Escrow payment is appropriate when the information or the goods provided have a substantial value. The payment by credit card or bank transfer goes to an intermediate `escrow’ agent, as does the information or a token for the merchandise. The escrow agent will match guaranteed delivery to the customer of the actual merchandise with guaranteed payment to the supplier. When both delivery and payment cannot to be repudiated the escrow agent will release goods and funds simultaneously. The escrow agent must be trusted, and is complementary to the information agent.
5) Transactions requiring modest payments, as discussed earlier, are handled adequately without explicit escrow services, based on trust and tolerable losses if the trust is violated. A mediating agent, if employed, serves both as an information service and increases the trust level that the consumer has in listed suppliers.
6) Very small transactions could be handled in the same way, and many credit-card companies do not now limit the minimum charge, and may in fact not allow vendors to set minimum limits. However, many information services have potentially very low transaction prices, and those are unattractive for these companies. Examples are copyright fees for papers (on the order of $1.-), participation in a game, or single instances of newsletters. We can envisage incremental charges being a fraction of a cent. The cost of processing transactions includes careful audit trails and assumption of risk, but can be lowered by transferring the risk of loss from the credit-card company to the other parties:
a. Risk is assumed by the vendor: If the consumer fails to pay, the vendor is not reimbursed. Since the increase in market should greatly offset any losses, most vendors would gladly accept such a risk.
b. Risk is assumed by the customer: The customer provides a `wallet’, with limited content, and has no recourse if the goods are not delivered.
7) Subscriptions are suitable when the customer and vendor intend to establish a long-term interaction. However, the initial contact is inhibited, since a long-term obligation requires more thought and trust. Some companies provide for a step-up to a subscription [Morningstar:99].
All of these techniques are inappropriate in some domains. Payment may differ based on representation. A low resolution image may be cheap or free, but one suitable for exposition can carry a high price. An author may offer his material free for perusal on the web, but want to charge if many printed copies are distributed in a training course.
For many information services the highest level of payment guarantee is not needed. There is no loss of tangible or irreplaceable value when the customer avoids payment for the information. For instance, much copyrighted information is xeroxed, without reimbursing the actual sources.
A reservation made for an item in limited supply, say, a flight, a restaurant, or a concert, which was subsequently not attended and paid for has a cost to the supplier if other customers were rejected or dissuaded. Schemes to avoid a payment that is due to a vendor or to default on delivery to a customer exist for all practical techniques. If the loss due to a failure to pay is small and such events are likely to be infrequent, then it is best to ignore them.
Many of these schemes can be understood using a single model, helping an innovator to select what methods are best in a specific customer-vendor domain [KetchpelGP:97]. Many of the software pieces and services are available as well. However, integrating them into an electronic commerce system is still hard. We find that the majority of corporate web-sites provide product information, but no path for on-line purchasing.
2.3 Education
Education is an enterprise that affects a large fraction of our population, and that fraction is increasing as society and technology change and require frequent updating of one’s skills. Even the assumptions about a student’s future options, made when entering college, are likely to have been overtaken by the time of graduation.
The information technology that will be used for modern education will adopt many concepts from entertainment: reliance on graphics, interaction, instant replay, multiple paths to reach goal, etc. [Brutzman:97]. The initial uses of the Internet in education are simple, and similar to access requests by scientists and consumers [Perrochon:96], but material specific for on-line education is being developed by a variety of places [diPaolo:99].
The tool providers will have to reengineer the tools developed for creating entertaining games to make them suitable for authoring by teachers. Much work is required by educators to present and maintain educational material [VernonLP:94]. The market for an educational product has to be larger than a single classroom to be viable. Such markets now exist in industrial training, where students cannot be brought together at one time in one place. Acceptance of distributed high-quality academic material will start where colleges cannot cover all topics of interest to their students, and will broaden as successes are attained.
The potential loss of individual teaching opportunities is already causing reactions in some teacher organizations who rightfully fear that acquisition of costly material from remote institutions will diminish their interaction with students. Such concerns will delay the adoption of information technology in education but cannot halt it. Education today is based on information in books, although five hundred years ago some reputable authorities did not expect printing to be useful [Hibbitts:96]. Electronically mediated information is likely to become the principal carrier of information for education, and effective teachers will learn how to manage and exploit it. How these capabilities will change the process and structure of education is hard to predict, but it seems unlikely that another hundred years hence much time will be spent by teachers standing in front of a class and holding forth.
The tools that information technology has to provide to serve education are similarly uncertain. It will be important for the industry to track changes and provide the means to bring education forward. Primary needs will include authoring tools for materials in all the media that will be used. It should also be easy to insert simulations and present the results in a visual meaningful form [CypherST:99]. Most of the material will be copyrighted, but obtaining permission to use must be convenient.
2.4 Governmental Services
The role of government is to serve the population, and allocate resources to projects and services that are of broad value. The resources are provided by the public so that it is important to make information available that will let people know what is happening in their neighborhood, their towns, and their country [AlbertsP:97]. The amount of information collected by the government is enormous, ranging from census data on individuals to cadastral information about land ownership and topology [RamroopP:99]. However, the actual implementation of useful services has not progressed very far, only bits and pieces are available. Recently adoption of standards, as OpenGIS, promises to enable a greater degree of integration in the provided information. Many of the information technology tools required for government are identical to those that can serve business and education [Perrochon:96]. We see, however, some unique needs in the area of planning and long-term record keeping.
2.4.1 Projecting Outcomes Government can count on long-term income and is hence capable of executing plans that take a longer time and require more resources than private enterprises. Even if the work is executed by private enterprise the costs will be borne by the public. Public support requires public understanding. Traditional documents and current data are inadequate to fully convey the implications of governmental investments. Since the effects of planning are not immediately visible, government agencies must provide to the public information about the plans and their expected benefits and liabilities.
Tools for planning often involve simulations of various types. Making the results of simulations accessible to planners and the public is important, but not well achieved today. Plans have a wide variety of outcomes, depending on initial assumptions and parameters. Documents can never list all possible future outcomes. Promoters of a specific vision will only publish the results of their plans, and much of the public is rightfully suspicious of the validity of these projected outcomes.
Making the simulations available on-line, and letting accessors see and change the underlying assumptions and parameters can greatly increase knowledgeable participation in the political process. The tools needed for such information may be similar to those used in educational simulations, but will have to access actual government databases.
For all government services scalability will be an issue. When government services are free, there are no restraints on access demand. The number of customers can rise rapidly when an issue of public interest arises. The information technology tools used by the government for informing the public must be able to be rapidly reconfigured to provide the expected services.
2.4.2 Archiving Government also has a responsibility for archiving and preserving historical data. Its own records represent much of our intellectual heritage. Corporate and academic records of activities, development, and research may have long term value as well, although we cannot predict what will be useful when [ChenEa:99]. Since the benefits are for the future, it is hard to expect more than minimal archiving, especially if no funding is provided. For instance, NASA space scientists were encouraged to maintain long-term records for secondary uses, but since they were not funded for continued services, NASA has taken on the responsibility.
As the world moves towards digital storage of all documents, new modalities of loss of data arise: electronic media deteriorate, the devices that read the media become obsolete and can no longer be maintained, the software that is needed to interpret documents and images changes and is not carried over to new operating systems [Rothenberg:96]. Numeric values may be represented in formats that are no longer in use, making their use in integration and projection difficult. Today already documents in older versions of Microsoft Word cannot be read by current software, and yet, the British Public Records Office (PRO) appears to use Word 3.1 as a base format [FreskoTCM:98]. The PRO addresses this issue by bundling the software and ancillary files required to read the documents into the archive. However, this assumes that suitable hardware and operating systems will be available for that software. Encapsulating the entire infrastructure, and then using emulation of old hardware on more modern devices can solve the problem of preservation, but will not support routine access.
The technology of printing created the redundancy that preserved most of our paper documents. Even when a library burned down, spare copies were available. Easy access to remote net sites reduces the need for redundancy. The cost of storage is sufficiently low that redundant storage is feasible [Kahle:97]. Copying of data may violate copyrights and privacy concerns [Pockley:96]. Continued readability of the formats used and indexing becomes the major concern [ChenEa99].
Use of public instead of proprietary standards can mitigate the problem, but even they will change over time. Systematic migration of content to current media is a complementary task, but not part of routine workflow in most enterprises. To integrate historic information that has been preserved into modern information processing systems is going to be difficult as well. Terms and metrics used in the past will have changed, so that historic data will have to be interpreted in its own context and transformed to be useful. Some knowledge exists and can be used to keep old data useful. For instances, changes in the ways the budget is calculated, that the GNP is estimated, or that the cost-of-living is computed are known. Software to routinely apply the needed corrections would make historical data more useful. Many deficits in our knowledge are only discovered when projections from a historical record look suspicious. It may take software and data `archeologists’ to find and understand records from the past that become of interest in the present.
The issue of preservation is not restricted to government, although it has hit governmental agencies, as NASA, first [Behrens:97]. Information businesses, as newspapers, have traditionally maintained archives, and now find it easy to charge for retrievals [USAToday:99]. Mining and manufacturing businesses have formal obligations to preserve records, especially those dealing with their effect on the environment. Medical records remain of value throughout the life of a patient, and records of epidemics have an indefinite value. Individuals will become concerned about archiving and preservation when they find that the digital snapshots they took of their children can no longer be read on their new PC. Going back to paper is unwise and infeasible in practice, since the quality will suffer and dynamic information, as video, speech, and 3-D representation, cannot be stored that way.
In many cases, the mere volume of data that might be preserved will overwhelm archiving projects. Selecting limited amounts for archiving is hard, since for the majority of data all possible future uses cannot be foreseen. A simple attitude is just `to save it all’, but that increases the cost of preservation [Varon:99]. To be able `to search it all’ later also requires keeping the associated software, linkages to ancillary information, and indications of context. Effective tools to help government, businesses and individuals manage their historical record, and integrate such management into their routine workflow do not exist.
3. Consumer Reaction
In this section we focus on the individual consumer. Individuals can be partitioned into a wide range, from a professional who is focused on work, to a teenager who, after school, focuses on entertainment. In practice the groups overlap quite a bit. Many professionals use their laptops on airplanes to play games; and teenagers perform research or even start Internet enterprises at home [Morris:99].
3.1 Expectations
The expectations of the consumer are fueled by the popular and professional press, namely that any need, specifically in the domain of information, can be satisfied by going to the computer appliance and in few seconds, satisfy that need. What are those needs?
3.1.1 Professional Needs Professional needs include information to get one’s work done expeditiously. Many professionals work in an enterprise setting, and these needs are discussed in the next section. But the modern professional has needs that distinguish the individual from the business participant.
An increasing amount of work will be done from the home. Full- or part-time `telecommuting’ will become the norm for information workers, as communications costs decrease and roads become more congested, specifically in the urban centers and airport neighborhoods favored by business enterprises. The lifestyle advantage obtained by avoiding hours of commuting every day will become increasingly valued. As more women enter the workforce, and have fewer children later in life, both men and women will trade the social advantage of a workplace setting for the advantage gained in family life. To be effective the need for information systems that can approximate and improve on the office setting at home will greatly increase.
Personal needs include information to obtain goods or services for one’s household, for the family and friends, for travel, and for entertainment.
3.1.2 Consumer Needs The need for goods is increasingly satisfied in modern society, especially in developed countries. Services that can save time, make life easier, or provide entertainment become more valuable in proportion [Wulf:94]. Information pertaining to services is more subjective, and quality differences are more important. We discussed in Section 2.2.3 the reporting of quality in electronic commerce, but quality issues pervade all services.
Types of services for which the Internet has started to dominate are in providing information about current events, public transport schedules, exhibits and performances, and news of particular interest not provided through TV or local newspapers. Information technology allows the formation of `virtual communities’, with low entry and exit costs, so that interests of relatively small groups, be they cultural, religious, medical, ethnic, or based on a hobby – say restoring vintage MG sports cars – can be served.
For these services information has to be up-to-date. The consumer wants to be assured that travel is on schedule, or what the delays are. Effects of weather or equipment failures must be included as soon as feasible. If seats are being reserved, the place must be guaranteed, and conflicting reservations locked out.
Technology to enable such requirements exists, primarily from the database arena. Integrating such technology into Internet systems is feasible, but requires some care to avoid performance problems. Smaller sites cannot afford the prices of professional maintenance. If such sites want to collect fees for services, the required linkages must be easy to integrate and the method for payment must be simple for the customer.
3.1.3 Mobile Support People spend considerable time on the road, in their cars or in public transportation. Much time is spent during commuting, where the individual is shifting from being a consumer to being a professional, or vice versa. Services to be provided in mobile situation hence span the range of the prior two categories, but are also constrained by two bandwidth considerations:
1. the mobile location is less likely to have reliable and capable connections;
2. the mobile user should not be excessively distracted.
The second condition is especially urgent if the client is driving.
If the mobile user is commuting in a car the best mode of presenting information is by voice. Voice restricts the rate of output to about 200 words per minute. Voice recognition is suitable for generation commands and structured queries. Local playback of the results in digitized form prior to transmission will be useful to catch errors before they incur major costs [LewisF:99]. Images, preferred for stationary application because of their high information density, can only be viewed occasionally when a person is driving. To avoid missing information, images as maps and graphics will only be replaced on a mobile display after a signal from the client.
If the mobile user is in a public vehicle, as a train or a bus, there is potential considerable interference with activities of others. Voice transmission, as over a telephone, must be used sparingly, and the environment is unlikely to allow speech recognition. Small devices, as palm-pilots and high capability telephones can present visual information. Pen input and limited keyboards can initiate requests. The bandwidth capability of devices and customers will be less. Tools to carefully select, filter, and abstract essential information will be a high value.
In mobile systems the need to be efficient in information transfer is most pronounced, but wasting time and attention with unwanted material exists for all consumers of the results of information technology [HadjiefthymiadesM:99].
3.2 Selection of High-value Information
The major problem facing individual consumers is the ubiquity and diversity of information. Just as the daily newspaper presents an overload of choices for the consumer in its advertising section, the World-Wide Web contains more alternatives than can be investigated in depth. When leafing through advertisements the selection is based on the prominence of the advertisement, the convenience of getting to the advertised merchandise in one’s neighborhood, the reputation of quality, personal or created by marketing, of the vendor, and unusual features – suitability for a specific need, and price. The dominating factor differs based on the merchandise. Similar factors apply to online purchasing of merchandise and services. Lacking the convenience of leafing through the newspaper, greater dependence for selection is based on selection tools.
3.2.1 Getting the Right Information Getting the right, and by implication, complete information, is a question of breadth. In traditional measures completeness of coverage is termed `recall’. To achieve a high recall rapidly all possibly relevant sources have to be accessed. Since complete access for every information request is not feasible, information systems depend on having indexes. Having an index means that an actual information request can start from a manageable list, with points to locations and pages containing the actual information.
The effort to index all publicly available information is immense. Comprehensive indexing is limited due to the size of the web itself, the rate of change of updates to the information on the web, and the variety of media used for representing information [PonceleonSAPD:98]. Automatic indexing systems focus on the ASCII text presented on web pages, primarily in HTML format. Documents stored in proprietary formats, as Microsoft Word, Powerpoint, Wordperfect, Postscript, and Portable Document Format (PDF) [Adobe:99] are ignored. Valuable information is often presented in tabular form, where relationships are represented by relative position. Such representations are hard to parse by search engines.
Also generally inaccessible for search are images, including icons and corporate logos, diagrams and images [Stix:97]. Some of these images contain crucial embedded text, that is not easy to extract [WangWL:98]. Only specialized vendors provide image libraries, and the quality of their retrieval depends much on ancillary descriptive information, perhaps augmented with some selection on content parameters as color or texture [Amico:98]. There are also valuable terms for selection in speech, both standalone and as part of video representations. Some of the problems can be, and are being addressed by brute force, using heavyweight indexing engines and smart indexing engines. For instance, sites that have been determined to change frequently will be visited by the `worms’ which collect data from the sources more often, so that the average information is as little out of date as feasible [Lynch:97].
Input for indexes can be produced by the information supplier, but those are likely to be limited. The consumer of information will typically find it too costly to produce indexes for their own use only. Schemes requiring cooperation of the sources have been proposed [GravanoGT:94]. Since producing an index is a valued-added service, it is best handled by independent companies, who can distinguish themselves, by comprehensiveness versus specialization, currency, convenience of use, and cost. Those companies can also use tools that break through access barriers in order to better serve their population. There is also a role for professional societies [ACM:99]. We will review current technologies for such enterprises in Section 3.2.7.
3.2.2 Semantic Inconsistency The accuracy and coverage recall is also limited by semantic problems. The basic issue is the impossibility of having wide agreements on the meaning of terms among organizations that are independent of each other. We denote the set of terms and their relationships, following current usage in Artificial Intelligence, as an ontology [WG:97]. Many ontologies have existed for a long time without having used the name. Schemas, as used in databases, are simple, consistent ontologies. Foreign keys relating table headings in database schemas imply structural relationships. Included in ontologies are the values that variables can assume; of particular significance are codes for enumerated values used in data-processing [McEwen:74]. Names of states, counties, etc. are routinely encoded. When such terms are used in a database the values in a schema column are constrained, providing another example of a structural relationship. There are thousands of such lists, often maintained by domain specialists. Other ontologies are being created now within DTD definitions for the eXtended Markup Language (XML) [Connolly:97].
A major effort, sponsored by the National Library Medicine (NLM), has integrated diverse ontologies used in healthcare into the Unified Medical Language System (UMLS) [HumphreysL:93]. In large ontologies collected from diverse sources or constructed by multiple individuals over a long time some inconsistencies are bound to remain. Large ontologies have been collected with the objective to assist in common-sense reasoning (CyC) [LenatG:90]. Cyc provides the concept of microtheories to circumscribe contexts within its ontology. CyC has been used to articulate relevant information from distinct sources without constraints imposed by microtheories [ColletHS:91]. That approach provides valuable matches, but not complete precision. Most ontologies have associated textual definitions, but those are rarely sufficiently precise to allow a formal understanding without human interpretation.
Inconsistency of semantics among sources is due to their autonomy. Each source develops in its own context, and uses terms and classifications that are natural to its creators and owners. The problem with articulation by matching terms from diverse sources is not just that of synonyms – two words for the same object, or one word for completely different objects, as miter in carpentry and in religion. The inconsistencies are much more complex, and include overlapping classes, subsets, partial supersets, and the like. Examples of problems abound. The term vehicle is used differently in the transportation code than in the building code, although over 90% of the instances are the same.
The need for consistent terms is recursive. Terms do not only refer to real-world objects, but also to abstract groupings. The term ‘vehicle’ is different for architects, when designing garage space, from that of traffic regulators, dealing with right-of-way rules at intersections. A vendor site oriented towards carpenters will use very specific terms, say sinkers and brads, to denote certain types of nails, that will not be familiar to the general population. A site oriented to homeowners will just use the general category of nails, and may then describe the diameter, length, type of head, and material.
Inconsistent use of terms makes sharing of information from multiple sources incomplete and imprecise. Forcing every category of customers to use the same terminology is inefficient. The homeowner cannot afford to learn the thousands of specialized terms needed to maintain one’s house, and the carpenter cannot afford wasting time by circumscribing each nail, screw, and tool with precise attributes. Mismatches are rife when dealing with geographic information, although localities are a prime criterion for articulation [MarkMM:99]. Many ontologies have textual definitions for their terms, just as found in printed glossaries. These definitions will help readers, but cannot guarantee precise automatic matching, because the terms used in the definitions also come from their own source domains. The problems due to inconsistency are even more of a hindrance to business than to individuals, who deal more often with single instances, as discussed in Section 4.1. Research tasks to deal with semantic inconsistency are indicated in Section 8.3.
3.2.3 Isolation Information stored in an Intranet, behind a firewall, is not accessible to the public search engines, as are sites that explicitly forbid access in their headers. Systems that extract information dynamically out of databases or other sources also create unwittingly or intentionally barriers that make the actual data inaccessible for indexing. Where limited access is intentional the requester cannot argue, but much valuable material is not accessed because its interface, its representation or its access paths do not allow indexing. For instance, the entire content of the Library of Congress is hidden behind a web page that presents a query engine. A customer who knows to search there will be served, but none of the material will appear in the information returned by one of the web-based search engines, which provide the primary access path for most consumers.
3.2.4 Suitability The suitability of the information for use once it is obtained also needs assessment. Medical findings of interest to a pathologist will be confusing to patients, and advice for patients about a disease should be redundant to the medical specialist. Some partitioning for roles exists now; for instance Medline has multiple access points [Cimino:96]. But smart selection schemes might well locate information via all paths, and most information that is publicly available is not labeled with respect to consumer roles, and it may even be presumptuous to do so.
There is hence a role for mediating modules to interpret meta-information associated with a site and use that information to filter or rank the data obtained from that site [Langer:98]. Doing so requires understanding the background and typical intent of the customer. Note that the same individual can have multiple customer roles, as a private person or as a professional.
3.2.5 Quality-based Ranking Assessing the quality of information and the underlying merchandise and services is an important service, as discussed in Section 2.2.3, and should be integrated into mediating services. Here three parties are involved in the module:
The latter must understand the sources as well as the categories of customers, and also be able to respond to feedback from the customers [NaumannLF:99]. Tools to help rank the quality of data by a wide variety of source and customer attributes should be easy to insert.
3.2.6 Determining Unusual Features Important for the Purchaser Unusual features are, by their own definition, varied, span a wide range, and are often omitted from the primary information. Examples may be the shade of a color wanted to match a piece of apparel, secondary measurements as size of a piece of furniture wanted for a specific odd location, the weight of an object to assess its portability, or its consumption of electricity or batteries. The lack of such information in on-line catalogs, or obtainable from call centers is astounding. Even for such obvious uses, as laptop computers, weight and actual battery life is hard to ascertain, and similar factors for desktop computers are impossible to find. Providing generous return policies, at high cost to the vendors, is one way of overcoming the lack of confidence generated by missing information.
There is an obvious tension in providing more specifications. Organizing the information to make it suitable for the consumer requires insight and care, often lacking in the engineers that design the goods and their marketeers. Many of the parameters are hard to specify, especially factors describing quality. If much detail, irrelevant to many, is given, then the consumer who is not interested will be overloaded, and may give up on the purchase altogether.
3.2.7 Tools for Selection and Search The need for assistance in selection relevant information from the world-wide-web was recognized early in the web’s existence [BowmanEa:94]. This field has seen rapid advances, and yet the users remain dissatisfied with the results. Complaints about `information overload’ abound. Web searches retrieve an excess of references, and getting a relevant result, as needed to solve some problem requires much subsequent analysis. And yet, in all that volume, there is no guarantee that the result is precise and complete.
Searches through specific databases can be made to be complete and precise, since the content of a database, say the list of students at a University, and their searchable attributes, as maintained by the registrar, can be expected to be complete. Not obtaining, say, all the Physics students from a request, is seen as an error in precision, and receiving the names of any non-Physics student is an error of relevance.
Effect of Sponsors Most of the search services are provided by companies that obtain their support by also displaying advertising, which means that the focus is initially on breadth – attracting many viewers – rather than on depth, providing high-value information for specialized audiences. Many advertising sponsors prefer having their advertisements seen by a more specific audience, and that is accommodated by having such advertisements presented at later stages in the search, when the customer has narrowed the search to some specific topic. This approach is likely to cause more effort to be expended on paths where advertisements are easier to sell.
Search Techniques There is a wide variety of search techniques available. They are rarely clearly explained to the customers, perhaps because a better understanding might cause customers to move to other searches. Since the techniques differ, results will differ as well, but comparisons are typically based in recall rather than on precision. Getting more references always improves recall, but assessing precision formally requires an analysis of relevance, and knowing what has been missed, which is an impossible task given the size and dynamics of the web.
Potentially more relevant results can be obtained by intersecting the results from a variety of search techniques, although precision is then likely to suffer further.
We briefly describe below the principal techniques used by some well-known search engines; they can be experienced by invoking www.name.com. This summary can provide hints for further improvements in the tools.
Yahoo catalogues useful web sites and organizes them as a hierarchical list of web-addresses. By searching down the hierarchy the field is narrowed, although at each bottom leaf many entries remain, which can then be further narrowed by using keywords. Yahoo employs now a staff of about 200 people, each focusing on some area, who filter web pages that are submitted for review or located directly, and categorizes those pages into the existing classification. Some of the categories are dynamic, as recent events and entertainment, and aggregate information when a search is requested.
Alta Vista automates the process, by surfing the web, creating indexes for terms extracted from the pages, and then using high-powered computers to report matches to the users. Except for limits due to access barriers, the volume of possibly relevant references is impressive. However, the result is typically quite poor in precision. Since the entire web is too large to be scanned frequently, references might be out of date, and when content has changed slightly, redundant references are presented. Context is ignored, so that when seeking, say, a song title incorporating the name of a town, information about the town is returned as well.
Excite combines some of the features, and also keeps track of queries. If prior queries exist, those results are given priority. Searches are also broadened by using the ontology service of Wordnet [Miller:93]. The underlying notion is that customers can be classified, and that customers in the same class will share interests. However, asking similar queries and relating them to individual users is a limited notion, and leads only sometimes to significantly better results. Collecting personal information raises questions of privacy protection.
Firefly provides customer control over their profiles. Individuals submit information that will encourage businesses to provide them with information they want [Maes:94]. However, that information is aggregated to create clusters of similar consumers, protecting individual privacy. Business can use the system to forward information and advertisements that are appropriate to that cluster. There is a simplification of matching a person to a single customer role. Many persons have multiple roles. At times they may be a professional customer, seeking business information, and at other times they may pursue their sports hobby, and subsequently they may plan a vacation for their family. Unless these customer roles can be distinguished, the clustering of individuals is greatly weakened.
Alexa collects not only references, but also the webpages themselves. This allows Alexa to present information that has been deleted from the source files. Ancillary information about web pages is also provided, as the author organization, the extent of use, the `freshness’ of updates, the number of pages at a site, the performance, and the number of links referring to this page. Such information helps the customer judge the quality of information on the page. Presenting web pages that have been deleted provides an archival service, although the content may be invalid. The creators of such webpages can request Alexa to stop showing them, for instance if the page contained serious errors or was libelous. Since the inverted links are made available one can also go to referencing sites.
Google ranks the importance of web pages according to the total importance of web pages that refer to it. This definition is circular, and Google performs the required iterative computation to estimate the scaled rank of all pages relative to each other. The effect is that often highly relevant information is returned first. It also looks for all matches to all terms, which reduces the volume greatly, but may miss relevant pages [PageB:98].
Junglee provides integration over diverse sources. By inspecting sources, their formats are discerned, and the information is placed into tables that then can be very effectively indexed. This technology is suitable for fields where there is sufficient demand, so that the customer needs can be understood and served, as advertisements for jobs, and searches for merchandise. Accessing and parsing multiple sources allows, for instance, price comparisons to be produced. Vendors who wish to differentiate themselves based on the quality of their products (see Section 2.2.3) may dislike such comparisons.
Cookies is not an independent search engine, but a device used by many engines and applications to track users’ activities between sessions. Cookies are left on the user’s computer by some applications and read at a later time by the same or a related application. For instance, a search for some movie, recorded in a cookie, can trigger an advertisement for a similar movie later. The use of cookies moves the storage of user-specific information to the user’s computer. It hence also changes the flavor of privacy concerns. Browsers allow rejecting of cookies and applications that generate cookies.
This list of techniques can be arbitrarily extended. New ideas in improving the relevance and precision of searches are still developing [Hearst:97]. There are, however, limits to general tools. Three important additional factors conspire against generality, and will require a new level of processing if searching tools are to become effective.
3.2.8 Factors Reducing the Effectiveness of Search Engines The three principal factors hindering the effectiveness of search engines are: unsuitable source representations, inconsistent semantics (as discussed in Section 3.2.2), and inadequate modeling of the customers’ requirements. Effectiveness must be increased if web-based information is to be routinely used in business settings. Overcoming these three limitations requires in each case combining automation with manual, value-added inputs, as discussed in Sections 8.3 and 8.1.
Representation of data in sources uses text, icons, images, etc. in a variety of formats. Text-based search engines are limited to textual representation of data [Nelson:97]. This means that information made available in proprietary formats, as Microsoft Word and Powerpoint, postscript, Adobe PDF, or embedded into images is not captured. The W3QL language permits the specification of web queries using forms, but unless the allowable query terms can be enumerated, most information hidden behind these forms remains inaccessible [KonopnickiS:98]. The search engines will fail to find much scientific information, for which web standards do not provide adequate formatting. As more information moves to visual representations there is a further lack of search capability. If the objective of the producer of the web page is to be found by the search engine, they will use simple ASCII in HTML and XML texts. Tricks used by aggressive sites to increase the chances of being rated high include adding and repeating terms in portions of the web pages that are not displayed.
Modeling the customer’s requirements effectively requires more than tracking recent web requests. First of all a customer in a given role has to be disassociated from all the other activities that an individual may participate in. We distinguish here customers, performing a specific role, and individuals, who will play several different roles at differing times. In a given role, complex tasks can be modeled using a hierarchical decomposition, with a structure that supports the divide-and-conquer paradigm that is basic to all problem-solving tasks [W97:M]. Research tasks to deal with such issues are indicated in Section 8.1.1 and 8.1.2.
3.2.9 Feature Overload Without clean models we encourage the addition of more and more features to our systems. Each feature is the result of some bright idea or engineering solution, but the resulting systems are confusing and unclear for the customer. Having models can help bridge the gap between the engineers, that are feature oriented, and customers who experience overload, not only of contents, but also of means on how to deal with the content. Feature growth in customer interfaces of information systems applications is similar to that in general software (Section 6.3), but less constrained by interface standards.
3.3 Privacy
Privacy is a major issue for individuals, and information systems are central to the issue. There is a sense that privacy should be protected, but legal constraints are few, although some have been proposed [Gore:99]. Most of the issues relating to privacy are not technological, but builders of information systems have to be quite sensitive to the issues of privacy. Understanding privacy issues requires knowing who the participants are, what their perceptions are of the losses and benefits incurred when making their information accessible, and the technical capabilities that exist. Often the losses may be personal and the benefits societal, as, for instance in sharing healthcare information.
3.3.1 Background Lack of concern for privacy can be, and has been, the reason of failure of a number of projects that were technologically feasible. A well-known example was the Lotus 1991 project to produce a listing of all people in the United States, with addresses and preferences [Culnan:91]. When this project became known, negative reactions of the unwilling participants were so strong that it was abandoned. Even recent governmental efforts to introduce a unique health-care identification number, perhaps modeled on the Social Security Number, have been stymied, and more complex, indirect schemes are now being proposed, that will satisfy some, but not all of the objectives envisaged by its proponents [Margolis:99]. The Social Security Number (SSN) itself is formally restricted to uses related to the social benefit system, but since that systems has been broadened so greatly, it is also used for Federal tax records, hence for State tax records, and for health care in the military. No major problems have occurred due to the use of the SSN in military health care, for instance, and still, further broadening of the use of the SSN leads to excited reactions in the U.S. In many European countries government involvement in private lives has a long history and such reactions are muted, but strong laws exist forbidding linkages of data from diverse sources. Some of these laws have their origin in the misuse of private data by totalitarian governments, but their acceptance is also based on emotional reactions to perceived loss of privacy.
Recent privacy issues go beyond identification of individuals. The design of the new generation of Intel chips provides a unique chip identification [Intel:99]. Such an identification has been requested, among others, by software distributors who wish to limit software piracy, by keying software licenses to specific computers. Again, a very negative reaction ensued, with the arguments that release of the number will allow vendors and governments to track communication activities performed on that computer, and presumably relating those activities to an individual. The final outcome of this argument is not clear. Intel is trying to assure the public that the release of the number can be blocked, although the frustrated reaction of Scott McNealy, president and chief executive of Sun Microsystems, a competitor, has been: "You already have zero privacy, get over it" [Markoff:99]. Similarly, the Microsoft Windows 98 operating system transmits at registration time information to Microsoft, which includes the identification number of the software, and associates it with personal information.
3.3.2 Participants The groups actively defending privacy are a mixed bag. There are very legitimate objections of groups that are truly concerned about civil liberties, say protecting individuals from being labeled by activities that they once performed, or mere accusations, but are now no longer valid. Many politicians have been unreasonably hurt by revelations of ‘youthful indiscretions’. There are people engaged in viewing pornographic material, by all measures a very large, but not a vocal group, that prefer privacy. There are hackers, who do not wish to be constrained in the range and flexibility of their computing activities. There are legal experts, seeing a new area of formalization of what is now a very poorly defined right. There are groups that see privacy invasions as an intrusion of large government into their lives. There are groups that see privacy regulations as a means to prevent multi-national companies from gaining excessive benefit from merging operations over multiple countries and continents. There is likely even be a criminal element that is quite willing to exploit the benefit of privacy for their benefit.
Open records are desired by vendors of software and other merchandise that wish to limit fraud and advertisers that wish to focus their messages to those most likely to react. Most public health officials see great benefits in aggregating health histories to determine the natural course of disease and the effects and side-effects of medication. There are firms, who in the process of developing and testing new pharmaceuticals, must relate activities and reactions of patients under surveillance over long time periods. And there are law-enforcement officials whose task is hindered by an inability to track criminal activities and criminals across legal and national boundaries.
The largest group, of course, are the people that are sympathetic to both the legal and the emotional issues. They are the recipients of the confusing arguments of the privacy debate, but their reaction has been modest. For instance, few people worry in practice about the cookies that web-actions are accumulating on their computer files (see Section 3.2.5), although simple tools exist to refuse or remove them.
3.3.3 Technological Aspects of Protecting Privacy Protection of privacy requires secure systems, and security requires reliable operations [Rindfleisch:97]. Current operations are lacking in all aspects [ClaytonEA:97]. But perfect software is impossible [DenningM:97]. Encryption of data provides arbitrarily secure storage and transmission, at the cost of longer encryption keys, delays for encoding and decoding, complexity of key management, and an additional chance of loss if the key is lost.
In order to obtain confidential material, or the key to be able to decode such material, the receiver must be authenticated as being the intended person, and authorized to receive the material. Improved authentication schemes are an active research and development topic. Most remote authentication protocols rely on public key encryption methods [KentF:99], and are quite strong, although research in the topic continues [NTT:99]. Local systems are often not as well protected, especially where many users share system software and data [RussellG:91], and keys and data are not well protected.
The converse is also an issue. There are sites that publish material that is offensive, either by being hateful or morally objectionable. While freedom-of-speech does not permit their closure, there is a need to recognize such sites and classify them. Many use tricks to intrude on legitimate searches. For instance, when seeking information on some actresses, one might be led to a pornographic site. Tools to aid in recognition of inappropriate sites can help search engine providers and individuals to tailor their searches around such material [WangWF:98].
There are many instances where collaborators have legitimate reasons for access to some data, but those data are not clearly distinguished from other data. For instance, a medical record will contain data of various levels of concern, from basic demographics to information about sexual-transmitted and psychiatric diseases, which most patients would not want to share widely. Some data from the medical record must be shared with insurance companies, public health agencies, and researchers, but such releases must be filtered [WangWL:98].
Privacy and security are also an issue in business and government, and even more often a concern in their interaction. Similar instances of shared data occur in manufacturing, especially in the setting of virtual enterprises [HardwickSRM:96]. Dealing with this issue requires innovative methods to match customers to resources, this time in a restrictive manner [WBSQ:96].
4. Business reaction
In manufacturing, the traditional needs are obtaining material and personnel, information on best processes to produce merchandise, and information on the markets that will use those goods. In distribution industries, the information needed encompasses the producers, the destinations, and the capabilities of internal and external transportation services. In these and other situations data from local and remote sources must be reliably integrated so they can be used for recurring business decisions.
4.1 Business Needs
The needs and issues that a business enterprise deals with include the same needs that an individual customer encounters, but also involve precision. In business-to-business interaction automation is desired, so that repetitive tasks don’t have to be manually repeated and controlled [JelassiL:96]. Stock has to be reordered daily, fashion trends analyzed weekly, and displays changed monthly. However, here is where the rapid and uncontrolled growth of Internet capabilities shows the greatest lacunae, since changes occur continuously at the sites one may wish to access.
Precision in on-line commerce requires having a consistent structure and a consistent terminology, so that one term always refers to the same set of objects. For example when we talk about equipment for a `sports-car’ both partners in a business transaction refer to exactly the same set of vehicles. But there is no law or regulation that can be imposed on all suppliers in the world that define what a sports-car is. There might be a professional society, say a sports-car club, which will define the term for its membership, and not allow in its shows a convertible without a roll bar to be entered. A manufacturer may sell that car as a sports car after installing a stiffer suspension and a nice paint job. To impose such a categorization on all vendors requires mutual agreements, which are difficult to impose.
Terms, and their relationships, as abstraction, subsets, refinements, etc. are specific to their contexts. We presented this problem in Section 3.2.2, defining this descriptive information as an ontology. Experimental communication languages that specify the ontology to be used, as KQML [LabrouF:94] and OML [Kent:99], provide a means to clarify message contexts, but have not yet been used in practical situations.
Intranets, operating within one enterprise, should have a fairly consistent ontology. However, we found that even in one company the payroll department defined the term employee differently from personnel, so that the intersection of their two databases is smaller than either side. Such aberrations can easily be demonstrated, by computing the differences of the membership from the respective databases. Within a specific business domain the contexts must be clear and the ontology unambiguous. When access to information becomes world-wide, and contexts become unclear, imprecision results, making business transactions unreliable. In large multi-national corporations and companies that have grown through mergers, differences are bound to exist. These can be dealt with if the problems are formally recognized, but often they are isolated, and solved over and over in an ad-hoc fashion.
4.2 Computational Services
Large software systems can no longer be built in a timely manner by collecting requirements, analysis, and then partitioning the pieces to a myriad of programmers, and finally integration and testing. Creating and managing large-scale software remains a task that requires many levels of expertise, well-defined processes, adherence to standards, and careful documentation. Even when all these pre-requisites are in place, overruns and failures are common. We hypothesize that after the Y2K effort few large software applications will be written from the ground up. Instead large system will typically be composed by using libraries and existing legacy code.
A change is occurring in practice, namely that large systems will be created by composition from existing resources [BoehmS:92]. This change is most obvious in information systems, because the objectives tend to be well defined. A new information system is typically constructed by combining a database system with some computational capabilities, as provided by business objects or a spreadsheet, and making the results accessible via a browser [W:98P]. Gluing all of these base components together is still difficult, since the components are diverse, their interfaces awkward, and the linkages embody excessive detail.
Composition programmers in the future will use tools that differ from the tools used by base programmers. [Belady:91].
In composition existing resources are catalogued, assessed, and selected, and systems are assembled by writing glue code to combine them. If the resources are distributed the glue incorporates transmission protocols for control and data. Considerable expertise is needed for success: the composer has to understand the application domain, judge to what extent the requirements of the customers can be covered from existing resources, and often negotiate compromises. And then the composer has to understand and manage an overwhelming level of details of interfaces, options in the available resources, transmission protocols, and scheduling options.We see a role here for a high-level composition language [BeringerTJW:98]. The code being generated in this research project drives available Client-Server protocols, as CORBA, DCOM, and Java-RMI. Important components for such systems are mathematical modeling tools and simulations [WJG:98]. The intention of such projects is to make distributed computational software as reusable as information resources have become [GennariCAM:98]. New ways of paying for the use of software will also be needed, as already discussed in Section 2.2.2.
Being able to insert computational services into information systems will enable a broadening of the concepts of information technology and reduce the distinctions of databases and software. Figure 2 sketches the vision of a network itself creates significant added value [Gates:99].
4.3 The Effect of Y2K
Most publications have focused on the disasters that failure to deal with the date problems in the year 2000 (Y2K) may engender. More rational observers predict a slew of minor problems and discomforts, culminating in some business failures, but much less than a global meltdown. More interesting, for the long range, is the redeployment of resources spent at the end of this millennium on the Y2K problem to other areas.
In the two years preceding 1 January 2000, enterprises are spending between 30 to 80% of their non-operational computing resources on assessing, repairing, and testing issues related to the Y2K problem. A large part of these resources will come free as of that date, although residual problems will still have to be fixed. The main problem remaining will be in system interoperability, since there is no single standard to deal with the problem. The three common solutions are:
1. Moving to a true 4-digit representation, solving the problem for the next 8000 years. This principled solution requires updating of all files that used 2-digit formats, or installing a mediating front-end to carry out conversions dynamically. These front-ends will be replaced in time, since their cost is obvious, but the resource drain will be distributed over time.
2. Deciding on a cut-off year, say 1945, and treating all dates prior to 1945 as falling in the range 2000-2045. This fix avoids rewriting most old databases, and defers the problem to the next generation. Since enterprises will differ in the setting of the cutoff date, future problems will appear to be distributed, and not much attention will be paid to the problem. Problems, when they occur, will be hard to fix since the personnel involved will have retired by then.
3. Inserting a code into two-character fields to mark post-2000 dates. This will typically solve the problem for 1000 years, but the code for its interpretation is awkward and is likely to lead to errors and maintenance problems. However these costs will be dispersed and not require major expenditures, although legacy programming talent will have to be retained.
Given the three alternatives, the major remaining cost of the Y2K issue is dealing with interoperation of enterprises that use differing schemes. Again, these won’t consume major resources, but will hinder the flexibility of future business-to-business communication.
Given the rapid cost reductions there will be substantial free resources available for investment in new applications. A limit will be the availability of staff capable of many types of modern development. Most programmers employed in solving the Y2K problem are poorly qualified to deal with the world of ubiquitous computing and Internet access. Depending on corporate policies it will take some time to retrain or shed obsolescent staff.
Purchased, standardized Enterprise Resource Management (ERP) software has seen a rapid growth of acceptance during the initial phases of the Y2K conversion. It allowed replacement of obsolete, non-Y2K compliant applications with standardized modules. Limited adaptation to the needs of a particular business is common; the business practices have to adapt as well. Extreme adaptation is costly and risky. With standardized software, enterprises no longer distinguish themselves by the computational aspect of their software capabilities. At that point differences in information acquisition and utilization become paramount.
While we cannot predict exact amounts, it is certain that substantial funds will become available for suppliers of innovative information technology. The companies that had to focus on legacy software will feel the need to update systems and improve customer access and interaction. Many of these companies will have to contract for external services, as capable people find it more attractive to work in small, modern enterprises.

Figure 2: The world wide information network and its participants.
5. Government and International Reaction
Governments and large, multi-national companies have systems that are large, increasingly interrelated, and represent a huge investment. Here the issues presented in Section 4 become even more convoluted.
5.1 The Network as the System
For large organizations networks have become essential [LockemanEa:97]. Networks provide linkages in a variety of ways, defining their architecture. A common, simple, architectural view is to regard the network as a blob and the customer and services as external attachments to that blob. Two-way linkages, as exemplified by client-server architectures are the dominant structure. Since most servers have multiple clients, and some customers employ multiple servers, the network structure starts resembling a net, as was sketched in Figure 2. Many of these services will be inside the networks that connects all customers and resources, so that, although we should not allocate participants narrowly to places inside or outside of the network.
However, there will be more and more intermediate services, as discussed in the prior sections. Those services will be within the net. An individual application will use multiple internal services, and the services in turn use multiple sources, but can still be configured as a hierarchy. Internal and external nodes will be shared. The global computing system will hence be a complex network. Such a network will have no central node and no central management. Customer applications can be built rapidly from these resources, but their maintenance will be difficult if they use services that are not stable.
New tools for locating, building, configuring, monitoring, reconfiguring, and releasing component resources will be needed. If applications are to be long-lived careful attention has to be given to their maintenance. Since components will not be owned by the customers, new contractual relationship will need to be developed [ChavezTW:98].
While these concepts seem difficult to support, the current situation is worse, where the maintenance cost of large systems exceeds their acquisition cost by several orders of magnitude.
5.2 Legacy Systems
Large organizations will always have legacy systems: systems that are of value, although written using obsolete technology. By the time one of them is replaced, other systems will have moved into legacy status. Attempts to get rid of legacy systems are futile, so it is best to seek architectural solutions that make legacy components acceptable and productive. Technologies as outlined in Section 4.2, that provide composition, can be adapted to deal with legacy systems, if they allow the incorporation of large components.
Often the interfaces of legacy systems are poor, so that wrappers are required. Functions to be supported by wrappers include providing input in a suitable form, initiating execution, and then gathering and forwarding the results. It is hard to provide general guidance for wrappers, but the use of templates is effective [AshishK:97]. Templates for one class of legacy applications can be adapted for similar classes.
5.3 Differences in Natural Languages
Multi-national companies and many governments must deal with multiple languages. While English is becoming the lingua franca for scientific interaction, we cannot expect that all source documents will use a single language [Oudet:97]. Governments should present their information in all the languages of their constituents, so that they can participate fully. Trying to enforce a single language for all publications will not solve the problem, since the quality of the source documents will suffer when they are translated or written by non-experts.
It is unclear when automatic translation technology will become adequate for source documents. However, it seems well possible to translate index terms used for searching and articulation. Such intermediate services will help in making information from remote sources widely accessible.
6. Extrapolation of Current Technological Capabilities
In order to support the wide range of systems, we use hardware, operating systems, and applications software, and must balance their capabilities.
We do not see a fundamental reason why the development of more powerful hardware should stop. As individual components reach their limits, they can be replicated, and the volume engendered by the replication reduces the cost, so that in each range of computing, servers, workstations, routers, and personal computers capabilities will increase, while the system cost remains approximately constant. We will base this report on that assumption, although the rate of capability growth is harder to predict [BranscombEa:97]. In the end that rate may be driven by the added value that consumers, the purchasers, assign to the software that requires the hardware.
Networks. As more hardware is obtained, routing and connectivity become increasingly important. Networking issues are moving closer to the consumer side, and that requires simplification of the associated hardware and its interfaces. When networks existed only in large organizations, their management could be assigned to costly specialists. If 24 hour, 7 day per week service is needed, a staff of several people is required, as well as hardware for backup in case of failure, and management to make it all work.
Today even small offices have networks, and those are maintained by the available enthusiastic computer user in the office. Since many homes now have multiple computers, but perhaps only one Internet access point, printer, and scanner, such installations are managed by the families’ teenagers, if they are lucky enough to have them around. In both cases, the pure hardware aspects are often manageable, but problems with software interfaces abound.
We can expect that in many offices and homes there will be a computer to provide the external network connections. Such a computer can also provide the value-added functions that are specific to a specific business or family. Backup for protection from disasters operation may be purchased from outside services, as indicated in Section 8.7.
Closely allied to the hardware are operating systems. Application software can only reach the hardware through the operating system. With many vendors producing hardware, it is the operating systems that control access to that hardware. Operating systems provide most of the functionality associated with computer systems, and have become very large and complex. While at one time each manufacturer would deliver their own operating system in order to deliver their own distinctive functionality to the applications, the complexity of the systems, and desire of the users to be independent of vendors has curtailed these efforts. Today only few operating system families remain in general use:
Efforts to introduce newer, simpler and cleaner operating systems, as NeXT OS, have been stymied. The low cost and broad acceptance of Windows makes such investments risky. The openness of UNIX makes it the choice for introducing innovations that require operating systems adaptations. While at one time manufacturers using UNIX had their own development groups, today a few UNIX vendors dominate, which will in time reduce the incompatibilities found in UNIX versions. Only occasionally does a new system version appear, as the LINUX implementation of UNIX. Market penetration of such new technology is difficult, in this case the freeware aspect is sufficiently dramatic to give the new entrant a chance. The dominance of Windows and UNIX in educational settings reduces the expertise available for incompatible alternatives.
Compatibilities and Networks Major system providers, targeting a broad range of customers, will support more than one operating system. For these providers compatibility of services among differing operating systems is a concern. The responsibility for such compatibilities is typically shifted to the periphery of the systems, namely where the network, printer, and remote servers are attached. In network interfaces the Internet protocols dominate now, although higher level protocols, as OMG CORBA – favored by UNIX users, DCOM – supported in the Windows OS setting, compete with each other and generic approaches as DCE, JAVA and the simpler remote procedure call (RPC) mechanisms.
Builders of information systems must be careful in selecting the right mix of operating systems and network technologies. Trying to support all is costly and confusing. Not supporting technologies favored by customers in their market range is fatal. Efforts to provide interoperability at a higher level are still in a research stage and hindered by the instability of operating and network interfaces [PerrochonWB:97].
Software adds value to computer systems. Only in the last ten years has the addition of value substantially translated to worth of pure software companies. While some software specialist companies have existed for 25 years or more, it is much more recent that their worth overshadowed that of hardware companies. Prominent examples are Oracle and Microsoft. Most hardware companies also deliver software, but increasingly the software they deliver is obtained from outside vendors, and only minimally adapted, typically to highlight some unique features, as compatibility with older products sold by the manufacturer, multi-media aspects, or portability.
New software is regularly needed by hardware vendors, partially to satisfy customers, but also as part of the technology push, to motivate purchases of new and more powerful equipment. Some such software may be novel, as multi-media capabilities, but much represents new functionalities, often minor, that are added to existing packages. The Microsoft Office suite is a prime example of the latter. Compatibility with new versions used by others, forces lagging customers to upgrade their software, and that often means that new hardware is desired as well.
However, an excess of features creates cognitive overload. Having features that one doesn’t know how to use is frustrating, and also leads to errors when they are invoked by mistake. This problem has been termed by Raj Reddy of CMU as `Being killed by featureitis’.
New software often demands more powerful hardware because features have been added that consume significant processing speed or storage. Examples are as-you-type spell-checking and layered undo and backup capabilities. While software algorithms continue to improve, that effect is not very obvious in software, since new capabilities are typically appended, and code for all old features is likely to remain. New, smaller hardware can motivate a reduction of features, as the Windows CE system for handheld machines and even more limited systems for palmtops.
Adaptation to standards is another motivation to improve software or move to new software. Whenever standards provide access to work of others, be it data or programs, there is a high value to moving towards that standard and discontinuing any redundant work that one has performed previously. To build such adapters rapidly one frequently resorts to `wrappers’, software which transforms data obtained from an output interface into the format required as input to ones own programs [ChawatheEa:94]. Wrappers can also be used for software adaptation, by implementing the methods needed by a client at the legacy software service [MelloulBSW:99].
Truly novel functions require novel software, but such events are rare and hard to predict. VisiCalc made the personal computer into a business tool, and Mosaic made it into an information appliance. While one is regularly asked what the next breakthrough or `killer app’ will be, we cannot attempt to answer that question. In time the killer app software becomes common, and the original version is replaced by software that provides easier use and wider applicability, as Lotus and Netscape, and the original innovation may be forgotten.
6.4 Balance
A requirement for progress, be it gradual or a `killer app’, is that hardware and operating systems capabilities and software and customer requirements match. Furthermore, information systems need a solid base of information that is important to a community that will be early adopters. For instance, Mosaic provided immediate access to preprints of high energy physics papers at CERN, an important resource to physicists all over the world, who had already capable computers and networks. The underlying hyperlinking concept was already promoted by Ted Nelson in 1974, but there were no ready resources, customers, nor convenient interfaces for them [Nelson:74]. Especially technologies that rely on automated learning need rapid access to wide and coherent population, otherwise the learning will be slow and diffuse.
Understanding the balance for an innovative product requires some perception of the future. Assuming infinite resources and interoperability is obviously unwise, as are efforts that optimize system aspects that are not on the critical path. It has been disappointing, for instance, that many artificial intelligence concepts have not taken hold, often because brute force approaches were simpler and required less expertise. Others have been integrated, so that they are no longer recognized as such, but also harder to transition [FeigenbaumWRS:95].
7. Unmet Needs
As systems, especially systems involving remote services, become increasingly complex, it is important to provide valid and clear models to the customers at all levels. A prime example of a model used in personal computers is the `desktop’, which transforms objects on one’s screen into document representations, with a set of methods as create, hide, file, delete, cut and paste, drag and drop. Recent extensions, supported through OLE (Object Linking and Embedding) and similar services, include insert object and edit object. This model does not aid sufficiently in conceptualizing multi-layer information models, where abstraction is the most powerful tool to manage the information universe.
Many modeling techniques exist, but are not yet integrated in the systems that provide services on the web.
7.1 Object-based Structuring
Object models support hierarchical abstraction. Hierarchical abstraction is the fundamental tool to deal with the real world. It organizes the world into a structure that allows the information worker to apply the divide-and-conquer paradigm fundamental to decomposing complex tasks into units that are manageable and composable. Object-orientation (OO) pervades modern system technology.
OO Software Modeling Object-oriented Modeling has become the prime methodology for modern software design. Not since the conception of Structured Programming [DahlDH:72] appeared, has a new software technology had a similar impact. Today many textbooks, professional guides, and Computer-Aided Software Engineering (CASE) tools support object-oriented software design. Object technology is also seen as a means for software integration, since object interfaces provide a higher level abstraction than traditional code segments [CeriF:97]. However, object-oriented data modeling has not kept pace, and we will illustrate a range of issues that still need research and development.
OO Data Modeling Object-orientation in software creation is simpler than object-oriented data modeling, because a specific program represents one approach to a solution, and hence one point-of-view. Data are commonly shared, and participants can hence approach the modeling from multiple points-of-view [W:86]. For instance, early relational systems supported implicitly multiple points-of-view, since they only provided the simple semantics of isolated tables [Codd:70]. The relational model complements the simple storage structure with algebraic manipulation of these structures. Moving to a calculus allowed automation in processing of "what" queries rather than following programmatic "how" instructions. Having an algebra also enabled the optimizations that were required. Alternate expressions over the tables define alternate views, which are mutually independent. Even now, relational processing capabilities remain weak. The relational SQL language has mainly one verb:
SELECT. UPDATE capability is severely restricted; they must have access to the full database, since views, essential to understand subsets of complex data-structures, cannot be updated in general.7.2 Network Data Models
To assure consistency among views there has to be more, namely a shared model. Entity-Relationship models provided quantitative structural semantics [Chen:76], but, until recently, this information remained in the design phase, and at most provided documentation for subsequent program creation. A formalization of the Entity-Relationship model, allowing matching of the relational transfers, the Structural Model [ElMasri:79] did not have a significant impact, since data modeling remained informal until objects started to emerge as first class data structures [BarsalouSKW:91].
Subsequent additions to relational systems provide the specification of integrity constraints, and these will limit the structural choices. For instance, combining uniqueness and a reference constraint will assure conformance to a 1:n relationship among two tables. Providing constraints is important for consistency and sharability. Still, the methods used to manage conformance remain outside of this model, so that software reuse is not encouraged. Structural compatibility does not imply semantic compatibility. Programmers have the freedom of defining semantics through the code they provide, but its sharability is hard to validate, and a certain amount of trust is needed in practice.
7.3 Modeling Computational Methods
In object-oriented programming there is a richness of methods that greatly exceeds the relational paradigm. The corresponding data models must allow much more semantics to be inserted and managed than in relational and E-R modeling, where models remained restricted to static structures. Those models, specifically, do not support the transformation process – the essence of data-processing. When the methods of transformation themselves are shared, interaction among participants moves to a higher level.
Research in automated programming is progressing, but has not yet reached a state where large programs can be manipulated. Computations are hard to formally describe where a mathematical underpinning is lacking. However, the most common functions in information systems are simple and can be formalized.
The most common operations are search, sort, merge, rank, and select and can be used to reduce data volume and provide more useful information to customers. Adequate formal models exists for storage, copying, replication, etc., of data. Another type of functions that can be well-defined are interpolation and extrapolation, as used to gain precision in data tables. For instance, tables of material properties are quite sparse. There are often many, say m, relevant attributes, but in most of the m dimensions values must be computed by inter-or extra-polation using simple formulas and limits, now found in footnotes of two-dimensional printed tables. Without such a computational assistance database retrievals would most frequently return null values. Because of that problem, materials selection is still performed manually within design processes that are otherwise automated. The resulting designs are not optimal with respect to materials usage [RumbleEa:95].
Such support functions can be included in intelligent information services, adding considerable value to data resources. Deciding what function to use when, is the hardest part of the problem, but a reasonable topic for research, as indicated in Section 8.2.1.
7.4 Information Models
Perhaps the major issue in information systems is the inability to control the quality of data that is available to the consumer. Information is best defined as data that transmits something not known to the receiver, and that will cause the state of the world of the receiver to be altered [ShannonW:48]. In information systems the receiver is taken to be a decision-maker. Information obtained by the decision-maker must hence be actionable, i.e., capable of causing an action to be initiated that would not have been performed without the information. The action in turn will affect the state of the world. The new state of the world may be observed and recorded as data [W:92].
7.4.1 Mediators Disintermediation causes that information, even if present somewhere in the world, be awkward to obtain. Just having search engines that rapidly submit volumes of possibly relevant information is not good enough. We need services, composed of software and people, that select, filter, digest, integrate, and abstract data for specific topics of interest [Resnick:97]. It is impossible, as demonstrated by Yahoo (see above) to cover all areas of human interest and do that task to sufficient depth. Specialist organizations will involve in areas as financial information, personnel management, travel, logistics, technology etc. [WC:94]. In these fields there will be further specialization, as in finance to provide information about investing in precious metals, bonds, blue-chip stocks, utilities, and high tech. There will be meta-services as well, helping to locate those services and reporting on their quality. We refer to the combination of experts and software to perform these functions, as mediators.
7.4.2 Functions The role of mediators in an information system is to perform services that translate data to information for multiple customers. To perform such services a number of functions have to be combined. Some of these functions require intelligent processing, others may rely on statistics [W:91]. To communicate with sources and customers, traditional middleware may be used [Kleinrock:94] . The distinction is that middleware connects and transports data, but a mediator also transforms the content.
Table 7.1 lists the major functions and unmet requirements for each of them. We visualize a customer information model, which is related to the type of user requests [ChangGP:96].
|
Needs |
Candidate Technologies |
Discover new resources |
Monitor and index public metadata which describes resource capabilities, contents and methods |
Select relevant resources |
Match available metadata and indexes of resource contents to leaf nodes in the customer information model |
Easy access to resources |
Wrapping of resources to make them compatible, exploit wrapper templates, bypass unavailable sources [BonnetT:98] |
Filter out excessive data |
Filters attached to the customer model; balancing relevant volume to the need for precision |
Identify articulation points |
Semantic matching of related concepts, use articulation rules provided by experts to match nodes |
Matching of level of detail |
Automatic abstraction so that sources match at articulation points within the customer model |
Integrate information |
Attach data instances to articulation points, combine elements that belong to the matching nodes, link to customer model |
Omit redundant data and documents |
Match data for content, omit overlap [ShivakumarG:96], report inconsistencies in overlapping sources |
Reduce customer overload |
Summarize according to customer model, rank information at each level |
Inform customer |
Present information according to model hierarchy, consider bandwidth |
Table 1. Unmet needs and candidate mediating technologies
7.4.3 Architecture The composition of synergistic functions makes a mediator into a substantial service. Such a service is best envisaged as a module within the networks that link customers and resources, as sketched in Figure 3. There is today a small number of companies building such mediators [W:98D]. However, the technology is not yet suitable to be shrink-wrapped and requires substantial adaptation to individual settings. Section 8 will discuss research and developments for mediated architectures.
Figure 3. An application instance composed by accessing mediated resources.
7.5 Mediation for Quality
As indicated in Section 2.2.3, describing quality is extremely different. Quality can be conveyed by corporate reputation, by guarantees given, by consumer reports, or by explicit metrics.
7.5.1 Trusting Quality. Many large companies have invested heavily in corporate images that project quality, and are able to market implicitly based on their renown. But that renown can be shattered. An example was IBM, which had built up an excellent reputation through the nineteen-seventies, but subsequently also acquired an image of not being up-to-date, although still costly. Much effort has been spent by IBM to at least regain a solid middle-of-the road position. Hewlett-Packard, having shifted from internal manufacturing of personal computers to their distribution as commodity products is facing the same issue today: if their products do not distinguish themselves in quality and service to those of vendors as Gateway and Dell, their reputation will be tarnished. For companies marketing a broad range loss of reputation in one area will greatly affect all areas, especially for consumers that cannot decompose the monolith sufficiently to make distinctions.
Information services here are ethereal, and mainly serve marketing needs. We will continue with describing some areas where more explicit information can be provided.
7.5.2 Guarantees If guarantees are given, trust is still required that the guarantee will be honored. The guarantees must be quite unconditional, so that no metric of quality is needed. There are organizations now that give a Seal-of-Good-Housekeeping to other companies. These companies have to be trusted as well, and the same issues hold, at one level higher, that were presented in the previous subsection. Escrow, as discussed in Section 2.2.4, may again be required if the objects to be returned are valuable. High shipping costs are a disincentive for the buyer if those are not covered by the guarantee.
Guarantees in the service arena are harder to specify. Services cannot be returned, and the person providing the service may not be able to carry the burden of non-payment. Again intermediaries may be needed to support a reasonable business model. Little software and systems support exists to help new service businesses.
7.5.3 Consumer Reports Quality can also be gathered by surveying customers. While such information always lags, and is easily biased, it represents the actual outcome evaluation. Bias occurs because of poor selection of customers and unbalanced response rates. Stable customers are reached more easily. Unhappy customers are more likely to respond. Questionnaires include leading entries, say, by starting with questions about safety of a car, subsequent questions about reliability will be viewed differently by the customer. It is difficult to eliminate bias from statistical reports [Huff:54]. Again, having a collection of effective tools that can be inserted into information systems to support experts that wish to provide services in aggregating and reporting customer-derived information would be a useful contribution.
7.5.4 Open Operations In some situations a wider degree of openness can help mitigate problems of trust and risk. For instance, the delivery of assemblies to a manufacturing line, repair parts to a utility or an airline, or medications to a hospital is often crucial. Letting the customer view the actual inventory at a distributor, provides a level of assurance that is much higher than that obtained by calling the distributor’s salesperson, who is likely to respond `We’ll get it to you in time, don’t worry’, no matter what the situation is.
Here issues of privacy protection, similar to those seen in general collaborating enterprises, arise. Not all information at the supplier should be available to all customers. Some of the stock may already be committed to a customer or have been manufactured for a specific customer. Suppliers may want to keep their customer’s names private. Manufacturing data may include confidential details. On the other hand, the customer may also not want to make novel requirements available, allowing suppliers and other competitors to gain too much information. Technologies for such protection are feasible, but require care and trust [WBSQ:96].
7.6 Maintainability
Maintenance of software amounts to about 60 to 85% of total software costs in industry. These costs are due to fixing bugs, modifications induced by responding to changing needs of customers, by adaptation to externally imposed changes, and by changes in underlying resources [ColemanALO:94]. Most maintenance needs are beyond control of the organization needing the maintenance, as new government regulations or corporate reorganizations, changes due to expanding databases, alterations in remote files, or updates in system services. Excluded from this percentage are actual improvements in functionality, i.e., tasks that require redesign of a program. Maintenance is best characterized by being unscheduled, because maintenance tasks require rapid responses to keep the system alive and acceptable to the customer. In operational systems, fixing bugs, that is, errors introduced when the programs were written, is a minor component of maintenance. Familiar bugs are bypassed and do not get much attention.
Maintenance is actually valuable, because it gives a longer life to investments made in software. Much software code has now been used for 20 years or more, although adapted and placed into newer packages and systems, so that now Y2K compliance must be checked, as discussed in Section 4.3. Devices with short lifetimes, as PCs, require little maintenance. For long-lived hardware, software-based controls are embedded so that when changes are needed, the hardware can be adapted. Long life and an ability to deal with complexity favor increased use of software, but imply a need for maintenance.
Given the high relative cost, preparing for effective maintenance should be a high priority when creating software. Since most maintenance deals with unforeseeable events improving the original problem specifications and requirements has diminishing benefits. Maintenance issues are pervasive, so that we cannot formulate a specific research direction. Having clean models, careful partitioning of domains, moderately sized modules will help. Specifically, modules should be maintainable by single individuals or coherent groups, so that no domain conflicts occur [W:95M]. Extending software tools beyond their original domain or cognitive focus will create unexpected failures. Having well defined domains, as discussed in Section 8.1 will certainly help in controlling maintenance costs, while still keeping the software up-to-date.
8. Research Needs
In this section we will list a limited number of general topics that warrant research and development. They are set at a higher level than simply solving instances of the problems and needs expressed earlier in this report. They will also address issues that transcend specific application domains. Inserting their results into actual systems is a distinct issue, dealt with in Section 9.
8.1 Models for Information Use
To deal with the flood of information that is becoming accessible to the growing population of computer-literati, it is not adequate to have systems that provide a superficially friendly presentation [HerrmanL:97]. Information systems must base their actions and reaction on a formalized understanding of the tasks being undertaken by a customer. A model is a materialization of a task description, structured so that an information system can identify where the task starts, what its subtasks are, and where the current state of the task is with respect to the model. Then the system can present information that is relevant to successor steps, switch abstraction levels when appropriate, back up gracefully when a sub-task fails, and avoid initiating subtasks that have failed in the past.
There is of course a plethora of possible tasks and of task models. Distinctions among tasks cover both the cognitive aspects, as seen when focusing on browsing, problem solving, problem definition, classification, authoring, etc., as well as the domain aspect, say finance, health concerns, entertainment, travel, information management, genomics, engineering design, etc.
Related to all these foci and topics is a wealth of information, which can only be effectively managed by imposing structure and value assessment of the information objects. The objective of providing information technology that can address this goal seems daunting, but is needed to bring the end-goal of initiatives as the Digital Library, the World-Wide-Web (in so far it has a goal), and many computational decision-aids into a form that will be beneficial to the human user. Such models will drive and enable Human Centered Intelligent Systems [FlanaganHJK:97].
8.1.1 Structuring the Setting To build usable models, we have to devise simple but effective structures for them. Simplification is a prime engineering concept: only simple things work as expected, and sophisticated tools and models are more likely a hindrance than a benefit [W:97M].
First of all we model the human as an individual engaged in a certain task type [ChavezM:96 ]. We employed the term customer for an individual engaged in a task in Section 3.2.2. A customer model is hence simpler than a general user model, which must recognize the interplay of many tasks and domains. The next simplification is to assume that a customer model is hierarchical. This is a major assumption, but can be made to be always true by a constraint: if the customer model cannot be hierarchically represented then the human must be engaged in more than one task. Once the hierarchical structure is accepted we have a wealth of tools available. Most applicable work in decision analysis, utility theory, planning, and scheduling becomes of bounded complexity if the structure is a hierarchy. Furthermore, within a hierarchy we can often impose a closed-world assumption, so that negation becomes a permissible operator in processing. Such assumptions are often made implicitly, for instance all of Prolog’s inferencing depends on negation-by-failure [KanamoriU:90]. The customer model makes the assumption explicit.
A human individual can engage in many types of tasks, but it is likely that a human is productive if engaged in a specific task for some time. Tasks are not necessarily carried out to completion before a task switch occurs, but some observable progress is desired. Here we have another formalizable concept, namely the marking in a hierarchy where an activity was interrupted, so that on returning to that task one can proceed, or rollback, as wanted. If much time has passed, the superior part of the task tree can be presented, so that machine and human can be synchronized.
8.1.2 Domains Domain specialization introduces a further simplification. Within a domain any term should have only one semantic meaning, acceptable to all customers working in that domain. A term as `nail’ is defined differently in distinct domains, as in anatomy – as part of a finger or toe -- and hardware – as a connector. We use a tautology to make the domain definition true: if there are inconsistent interpretations of a term, then we are dealing with multiple distinct domains.
By keeping domains coherent and hence of modest size we avoid many common semantic problems. We have many instances where effective ontologies have been created by specialists focusing on a narrow domain. Failures and high costs occurred when such focused ontologies were expanded in scope beyond their original intent. Establishing committees to solve ontological problems over multiple domains (using our definition) is likely to lead to unhappiness of customers and specialists, to whom a terminological compromise is of little benefit, as discussed in Section 3.2.6.
Examples of the problems encountered in scaling-up of valid simple concepts in computing is seen in object technology. Simple objects are attractive, because they can represent data and process constellations in what appears to be a `natural’ way. It is no coincidence that their internal structure is typically hierarchical. Inheritance of features in a hierarchical structure of multiple objects provides an effective conceptual simplification for their customers. When object information over multiple domains is integrated so that multiple inheritance has to be modeled, confusion ensues. Similarly, objects become unwieldy when large and serving multiple tasks. Many of the committees convened to design the `right’ objects in industry and government are making glacial progress and their work is likely to be ignored.
8.1.3 Partitioning and Composition Now that we have modeled the support of human information services, we need tools to extract and attach data instances from the resources in the real world and compose them to serve, first of all, specific tasks and domains. We model customer needs by extracting hierarchical customer-focused models out of the complex world of information resources [WG:97]. This can be seen as generalization of database view definitions; each single view represents a hierarchy [W:86]. We can create hierarchical objects from these views [BarsalouSKW:91]. Similarly, resources gathered from the web can be effectively presented as hierarchies of semi-structured data items [ChawatheEa:94].
A first goal for advanced information technologies is the representation and interpretation of these customer task models. For any hierarchy it should be possible to structure the domain-relevant units located by a search into an effective and natural structure for the customer. At the same time, task and domain switching must be recognized, and prior task models during a customer session must be retained to be re-enabled if the individual returns to a past customer model. Once data are partitioned into a clean hierarchy many valuable computational tasks are enabled. The methods for handling information in such structures are similar for tasks of human cognition and mechanical processing, although the scale can differ greatly.
Searching through a hierarchy has a logarithmic cost, and a factor that depends on the breadth of the tree at each level. When humans search the list at one level, their perception can deal with 7±2 items at one time. That means a tree of 10 000 items can be searched fully with 6 actions. That cost is acceptable to most customers. This performance depends, of course, on having the instances properly composed and linked into the task hierarchy. Longer lists impose a higher cost to the human, who must now search linearly [Miller:56]. Moving up and down the hierarchical tree changes the level of abstraction, and lets humans deal with tasks that seem to involve an unmanageable level of detail, say the total budget of a world-wide enterprise.
For automated search and processing the hierarchies can vary more, and should represent conceptually meaningful partitions. Annotations at the various levels can provide directions for processing algorithms. Items at the same level in a hierarchy can be identified as representing a complete, partial, disjoint, or overlapping subset. Where subsets are indicated to be complete and disjoint, totals and other aggregations can be computed and brought forward to the level above. Such computations support the human capability of abstraction, so that the budget can be presented. Such support is essential for planning, so that the effects of actions by management or outsiders can be rapidly reassessed.
8.1.4 Articulation. Once we have clear domain and task models we need methods to recognize switching of individuals to alternate customer models. They will typically be related, and then we must recognize intersections, where items belong to two models. A new domain being entered is likely related to a prior domain, so that there will be an articulation point between them. At an articulation point there will be some semantic match, even if the actual terms and representation do not match. Moving, for instance, from the domain of vacation travel planning for a trip segment to the airline domain the term flight is equivalent. Here the connection is easy, and either domain model could help in the match. But care is still needed, since a flight segment is at a lower level of granularity than the trip segment. As indicated in Section 4, precision in matching becomes essential in repetitive business transactions, where one cannot afford to spend human efforts to correct semantic mismatches every time.
Understanding articulation points is a service implicitly provided by experts, here travel agents. In any application where subtasks cross the boundaries of domain some experts exist that help bridge the semantic gaps. In human interaction such crossings are made implicitly by smart people. Even general reasoning relies on analogies from other domains. Converting human assistance in multi-domain crossings to automation will require a more explicit understanding of domains, consistency, and articulation than is common now. Section 8.11 considers a formalization of such concepts.
8.1.5 Summary Information presented to customers must have a value that is greater than the human cost of obtaining and managing it. More is hence not better, rather less, but highly relevant information is best. To help individuals, model-driven tools are needed to reduce complexity and overload. Modeling involves:
Task models are best built by domain specialists, who understand the content, using components that are effective for the cognitive focus in a task. Tools that support the building of these task models, and attaching computational, navigational, and display services to them should be developed by computer science efforts and delivered and supported by computer industries.
8.2 Mediation Technologies
In Section 7.4 we listed functions that will combat the effects of disintermediation. Mediators are human-managed software modules that provide information services to applications and their customers that carry out such tasks – now also referred to as reintermediation [Maney:99], a term that originated in financial markets. Mediators are often domain-specific, and should supply functions relevant to the intended customers [W:92].
While today mediators are largely handcrafted, there is a need to build them rapidly, and allow them to be rapidly adapted to business or individual customer needs. Since the selection and scale of functions needed varies, there has to be means for composing functions rapidly, and then initializing them with the domain knowledge that they need to perform their tasks.
8.2.1 Model-driven Mediation Ideally the knowledge required for mediation has been embodied in models, as presented in Section 8.1. Databases owe much of their success to the concepts of schemas, which provide a simple model to the applications and their programmers. Such formalized knowledge provides scalability and a basis for further extensions of database technology [SilberschatzSU:95]. Extending the model to provide a task model means that software work-flow can be driven automatically. Models can also provide links to thesauri, which can permit the mapping of ontologies used in the information resources to the terms appropriate to the customer.
The model, or models can also provide a valuable high-level tool to the customer. Today it is easy to get lost when trying to deal with the variety of data on the web. Providing a visual match between the current or prior task model and the data resources that are being employed can make the interaction much more powerful [Winograd:97]. Being able to show what is happening is even more crucial when failures occur.
To address the problems of dealing with change, increased automation is required. Matching resource models to customer models provides a direction to address that problem. Any automatic adaptation has to be done within the customer context, as expressed by the functions the customer requires. Modeling the functions is likely the hardest aspect, and will require multiple iterations of research, development, and feedback.
8.2.2 Broader Source Access We indicated in Section 3.2.5 that the many resources are not easily or directly accessible. Mediators can employ tools that recognize and deal with a wider choice of representation of the information stored on the web and in private collections. Such tools can bring to the customer information that is now in unsearchable formats as postscript, tables, graphics, images, video, and speech. Low cost methods to make some of the content available for search and indexing might be feasible, since for searching tasks perfection is not needed.
8.2.3 Warehousing Mediation services may have to employ caching or data warehousing technologies. If it is known that information at a site is transient, or updated at a schedule that does not match that of related data or the customer needs, then copying of data into local storage may be required. Formal handling of temporal mismatch will require concepts of objects that change over time, as indicated in Section 8.3.2. For basic web-pages some archival storage services might be delegated to Alexa or Google, but then the quality of their services has to be well understood. Warehousing research has its own agenda, although many subproblems overlap with those found in mediation [Widom:95]. In warehouses as well as in mediators consistency has to be achieved, so that customers are relieved from concerns that could overwhelm them.
8.2.4 Scalability It is important that the architecture in which mediators are inserted is scalable and maintainable [WC:94]. Many initial demonstrations of mediator technology used a single mediator and provided impressive results by combining, say three sources and supporting two applications. Such a design creates a central bottle neck, both in terms of performance as more customers find the services attractive, and in terms of maintenance, as more resources have to be dealt with. All resources change over time, some perhaps every couple of years, others much more frequently. Any mediator must be of a size that its operation can be maintained without excessive hassles, and that means that systems will have multiple, specialized mediators. Some mediators may provide information to higher level mediators as well as to customers. Having consistent interfaces will be valuable, although no single standard dominates today. The definition of KQML was such an attempt [LabrouF:94]; today XML is a prime candidate, even though the concept of alternate ontologies is only implicit, and alternate representations are not considered [Connolly:97].
8.2.5 Versions To deliver improved services, mediators will have to be updated as well. Some changes are bound to affect the customers, as new interfaces or changes in the underlying ontologies. Unwanted updates, scheduled by a service, often hurt a customer, even though in the long run the improvement is desired. To allow customers to schedule their adaptation to new capabilities when it is suitable for them, mediator owners can keep prior versions available. Since mediators are of modest size and do not hold voluminous data internally, keeping an earlier copy has a modest cost. The benefits of not forcing all customers to change interfaces at the same time are significant. First of all customers can update at a time when they can do it best. A second benefit is that first only a few customers, namely those that need the new capabilities will be served. Any errors or problems in the new version can be repaired then, in cooperation with those customers, and broader and more serious problem will be avoided [W:95M].
As encountered throughout this report, but specifically in Section 3.2, semantic inconsistency is a considerable hindrance to effective use of information resources and the prime barrier to business-to-business interoperation. It is a fundamental result of autonomy in large scale settings, and cannot be avoided. We hence have to be able to deal with it. While no solutions will be all encompassing, we indicate here three approaches that seem to have value: Ontology management, use of thesauri to help search and indexing, conflict reporting, and conflict resolution.
8.3.1 Tools to Manage Ontologies To recognize semantic differences we need first of all to know what the terms in the domains are, i.e., their ontologies, as introduced in Section 3.2.2. The importance of terms to manage information sharing is widely recognized. Major domain ontologies are in place, as the National Library of Medicine (NLM) effort for healthcare [HumphreysL:93]. UMLS, as many other ontologies, has been defined in the abstract, without considering a specific tool or a computable representation.
While there are many efforts to develop ontologies, there has been less work on building tools to manage ontologies. Some efforts are the Knowledge-finder [Lexical:99], [TuttleEa:98] for UMLS and Ontolingua [Gruber:93]. Unfortunately, many of these tools are naïve, in that they do not recognize the variety of contexts explicitly. The problem was recognized in the building of CYC [LenatG:90], and a concept named `microtheories’ was introduced to deal with the issue, mainly to better manage updates by diverse contributors. However, the search engine in CYC handles terminological inconsistency as an exception, so that precision is not improved unless explicitly dealt with. Ontology management is bound to become a more visible issue, and industrial strength software, with sufficient capabilities to serve specifically circumscribed domains in depth will be needed. As indicated in Section 8.2.4, XML is a candidate for ontology representation, and browsing tools for XML are appearing now.
8.3.2 Partitioned, Smart Indexing
As was discussed in Section 3.2.1, indexing faces an impasse. There is too much on the Internet to index it all by any single comprehensive service. It is even harder to keep such indexes up-to-date. At the same time semantic incoherence makes these indexes useless for precise retrieval. Likely solutions will involve partitioned indexing, focusing on one domain context at a time. A single context driven indexing engine will focus on sites and pages relevant to its concern, using domain-specific ontologies. Those ontologies should use the tools described in Section 8.2, but must also populate them with appropriate metadata, which will have to be maintained with care. Where metadata are not made available by the sources, they can be provided as wrappers attached to the mediators [Singh:98].
Meta services will be needed to supply candidate sites and pages to the domain-specific indexing engines. No such tools exist today, and the business model is not yet clear as well. However, since current information technology of web indexing has hit an impasse, some solutions as sketched here are bound to emerge and in time enter commercial practice.
8.3.3 Making Inconsistencies Explicit If the service gets data entries that should match, but there are some differences, it can be impossible to decide with sufficient reliability if one entry is better or which one is wrong. It is also possible that two similar entries actually refer to different objects. Sometimes there are valid reasons for a difference, say that observations were made at different times. In ambiguous cases integration is best avoided and both entries are reported to the customer, together with a source identification [AgarwalKSW:95].
At times the application can take both entries into account, or can make decisions based on local knowledge. In other cases it is best to inform the customer. If the customer makes a decision, that information can be fed back. To make the result of the decision persistent a mediator may simply remember it, or request the source to make a fix.
8.3.4 Algebras for Ontologies
There will be many applications that cannot live within a single ontology. For example logistics, which must deal with shipping merchandise via a variety of carriers: truck, rail, ship, and air, require interoperation among diverse domains, as well as multiple companies located in different countries. To resolve these issues we have proposed an ontology algebra, which uses rules to resolve differences in the intersection of base ontologies. The concept is not to force alignment of those base ontologies, but only present to the application consistent terms in the limited overlapping area. Typical intersections are terms used in purchasing goods and services from another domain, the example in Section 8.1.4 cited trips and flights. Terms only used in one domain need not be aligned, as sleeping compartment or in-flight movie.
When humans perform articulation, either on the phone or in direct interaction on the Internet, the problems are not widely recognized. For business-to-business transactions they will need to be solved, but there are already people who are informally doing such work. The rules that define an articulation are specific to narrow application contexts. Many such rule sets can exist, for instance one specific to logistics in drug distribution. The logical organization to be responsible for the rules which define such a specific `articulation ontology’ for, say, pharmaceutical drugs would be the National Drug Distributors Association (NDDA) in the USA. There will be a need for tools to manage those rules, and these tools will profit from the ontology services envisaged in Section 8.3.1 [JanninkSVW:98].
8.4 Supporting Decision Making
Information systems are typically justified as tools for decision-making. Providing correct and integrated information is certainly an important prerequisite, but does not support the full scope of work required by a decision maker. A decision maker has to be able to project into the future, since that is where benefits and costs will be incurred due to the decisions being made today.
8.4.1 Two-way Interaction To provide intelligent interaction for decision making, the customer requires additional capabilities from the task model. Decision-making is too complex to be fully automated. Balancing variables that have different metrics is a human task, for instance, deciding about investments in health care that can mitigate pain and enhance life. The decision making-system requires a conversation manager that can support two-way interaction. Since the customer should not be overloaded, the system may present progress visually as long as it can proceed.
The interaction should always present clearly the current state of the process. At any point, what-if queries should be permissible. Possible alternative paths should be clearly displayed. Having a hierarchical task model will help greatly in having an understandable situation. When the system is interrupted it must attain a clean state, and also allow rollback, if the customer decides that an undesirable path was taken.
If a path is clearly infeasible, it can be rolled back and the information created in its path can be deleted. However, rational decision-making requires also quantitative analysis of multiple paths. To get values for comparison, simulations may be employed. To deal with multiple paths the information models must recognize alternate possible futures.
8.4.2 Access to Simulations Tools to compute future states often require simulations. A wide variety of tools that help predict future results exist. They range from spreadsheets with formulas that step through future periods to large-scale, continuously executing simulations, as used in weather prediction. Many computational options lie in between. All of them should be made easily accessible to information systems that intend to support decision makers.
8.4.3 Multiple Futures The information model will actually have to support multiple futures. While there should be only one consistent past, alternate actions that can be made today, or caused by others, will lead to alternate futures. Extending the model beyond the effect of today’s actions, and including future possible actions and reactions creates a broom of future choices, as indicated in Figure 4 [W:99]. An information model to support a decision-makers’ projections must keep track of these alternatives, and value and label them properly. Labels should relate to the task model instantiation, promulgated in Section 8.1.1.
Figure 4. Information model extending into the future.
Once we have an information model that allows management of multiple projections, a number of novel tools can be provided to help the decision maker; we can sketch a few:
Research has produced and tested many technologies that can support such tools. Most have not been used on a large scale, since the information systems that require their use do not exist today. For example, methods to combine uncertainties from multiple sources have been studied. Temporal reasoning is another field where progress has been made, but rarely applied.
8.5 Post-WIMP User Interfaces
The current interface for customers of information systems has been built upon the metaphor initiated by Alan Kay in his 1969 thesis at the University of Utah and expanded subsequently by him at Xerox Parc. Parallel, significant, contributions were made by Doug Engelbart and his research group at the Human Augmentation Laboratory at SRI International. These concepts have been industrialized by Apple, Microsoft, and now the entire software industry. The customer interacts with a Window, Icons represent documents and programs, and the interface is controlled via a Mouse by a Person [Richards:99]. In many ways this interface materializes a vision presented by Vannevar Bush in 1945 [Bush:45].
We have projected rapid growth of computational capabilities, following Moore’s law, to that interface. Data storage is also experiencing exponential growth in terms of size, although less in terms of performance [?]. The capabilities of displays are nearing the limits of human perception. The means that people – with their limited capabilities to absorb, process, and create information – are becoming the bottleneck [Miller:56]
The problem with WIMP interfaces is that they demand much of human cognition. They are not yet at the level of say an automobile, which can be driven quite safely without thinking about it, although the information processing demands are quite high.
8.5.1 New Interfaces to Humans Post WIMP interfaces are expected to use 3-D world simulations, rather than 2-D desktops [vanDam:98]. They are now available to our children in their computer games, and we can expect that similar style interfaces will appear as that generation grows up, especially where real-world objects are being managed at the end. Interactive 3-D tools are already practical today for aircraft maintenance and architectural walkthroughs. Examples as scheduling travel, logistics, building management, etc. can also be easily envisaged using 3-D paradigms rather than indirectly via documents. Docking of drug molecules with proteins has been visualized, but developing a better understanding may benefit from 3-D interaction as well.
Information structures may also benefit from multi-dimensional presentation and interaction. However, our abstract concept easily becomes 4-, 5-, 10-, or more dimensional. Then such presentations must be able to map, shift, and rank the dimensions. New widgets will be needed to denote shifts, scale-expansion, and the like. Rapid feedback and transformations will be required at the client side.
Tools for 3-D interaction are being developed. Voice recognition capabilities are improving. Video input has been analyzed to recognize gestures, avoiding the need for gadgets [ZelenikFS:97]. The more specific to the task the interaction widgets become, the easier the interaction is learned. For instance, haptic gloves allow sensing of the texture of virtual surface, an attractive notion before buying clothes over the Internet. Perceptual inputs and outputs for many senses must be integrated for a high degree of realism, although the human mind and its imagination help greatly in overcoming limitations of virtual presentations.
Today, most perceptual interactions have been demonstrated on a small scale [Turk:98]. If eventually information technology is to support such interactions both the individual streams, sound, video, haptic, must be handled well and well synchronized together. Today there are no standards for the representation of such information. Not all people will wish the same type of interaction, so any standard should allow for interpretation of the contents in alternate representations. That is, of course, especially needed for handicapped users.
8.5.2 Ubiquitous, implicit Information Access The ultimate user interface is none, as we see in the processors embedded in cars, in washing machines, and other devices. For information technology we do expect that the applications include interfaces with resources and experts. The car may be connected to map servers, receive warnings about detours and traffic jams. The washing machine may adjust its operation to the weather prediction, for outside drying, or ask for advice on what chemical to use for removing a stain. The computer in our vest pocket may recognize the person we meet, decide if we know him or her, and provide us with information about prior interactions, perhaps picking up a past task model [Rhodes:97]. Today such interactions strike us as weird, but they might well become the norm.
How far such automation will or should go is hard to predict. Humans like challenges, and are traveling ever further from their homes to experience them.
8.5.3 Interfaces that Make Telecommuting Effective Much of the relevant hardware for working from home exists today, but its interaction is not always smooth. Essential equipment are, in addition to personal computing, economical printing, fax, voice, scanning, and low-bandwidth video capabilities; organizational tools that bind complex documents, including active components together into a clear and relevant structure. Software to keep documents on the office computer synchronized with those at home will be essential. These connections have to work for documents that are shared with others, and for document collections that are only partially replicated at home.
Much of the technology exists today in basic form, as Microsoft Briefcase and Lotus Notes. Improvements required are in interoperation standards for a variety of equipment, local and remote, as well as robustness in the face of communication and power failures [BranscombEa:97].
A logical extension of that directions is `ubiquitous computing’ [Weiser:93]. Ubiquitous computing implies that some level of information access should be available at all times, without disturbing activities of daily life. The bandwidth will differ, depending whether you are at home, commuting, or at a work site. So that you can be reached at any time, assuming that you wish to, you should have a permanent address. Some professional organizations provide a forwarding service from their site, so you have a permanent address at least within a professional life span.
8.6 Object-Oriented Technology
The emergence of common business objects, supported by OMG and vendor initiatives, heralds an acceptance of sharable object models and their methods. To the extent that this technology becomes accepted, the conceptual distance between programs and models will be reduced. Business models must express now functions and relationships that go beyond the static structures easily visualized in tables.
Since until recently relational systems and E-R support have well nigh ignored temporal computation, this area has been especially fruitful for data modeling. Here objects go through transformations over time, without losing their identity. Information in older versions is often of value, even though these objects no longer exist in reality and cannot be validated with respect to the real world. Most data describing these objects does not arrive in storage systems in real time, so that demands for strict consistency conflict with up-to-dateness. We have recently suggested that simulation access may be needed in cases where currency is more crucial to decision makers than consistency [AFCEA]. [WJG:98?]
8.6.1 Object Libraries The use of object libraries moves programming to a higher level. These business objects constrain tasks beyond the realm of traditional programs, since they must share data structures and content [W:99OO]. Here interoperation among vendor offerings will remain an issue for some time. Focused software vendors, as SAP, have reaped great benefits by providing domain-specific software with somewhat implicit, but fairly rigid models. Many customers are willing to adjust their processes to those models, in order to gain the benefit of shared software and especially the expectation of shared software maintenance.
As our systems become larger, more complex, and more interlinked we will also find that we will have to maintain our models beyond the design stage. It will become rare that software systems will be replaced as a whole, the cost and risks of doing so will be too great. But components will be updated and exchanged, requiring a clear understanding of the software that is not available for today’s legacy systems and cannot be accommodated by documenting the code alone. An open question that remains is how to document the decision process, for instance, the assessments that led to a design alternative not to be adopted. The widespread adoption of this approach, and the accompanying literature will help clarify the situation, but development has to proceed with care to reach the customers at the point where the benefits are substantial and the costs, for instance in maintaining interfaces with legacy systems, are tolerable [PapazoglouoST:99].
8.6.2 Temporal Reasoning While the relational model focused initially on snapshot data (t=0), most data collected now is kept to provide a historical record [LinR:98]. This means that a database object now has a range of values. Versioning of these objects is difficult at high abstract levels, since the time-stamps associated with base data will vary. Extensions to SQL, as TSQL, are becoming well-accepted, but have not yet been broadly employed [Snodgrass:95]. One reason for delays in adoption may be due to the existence of legacy systems, which are functioning, and hard to convert, especially if the temporal technology does not guarantee similar levels of application performance [SilberschatzSU:95].
Temporal operations are informally well understood, although their correct formalization requires great care. For instance, consider the handling of open intervals (common in human interaction) and closed intervals (needed for reliable computation if temporal granularities are mixed) [WJL:93]. Since analyses of time are so pervasive, it is important that information systems incorporate reliable temporal reasoning.
8.7 Managing Maintenance
Maintenance is the highest cost item in software, including information systems, and has to be explicitly managed. The range of maintenance costs is 90-66% of total systems costs, and will not be reduced by better initial specifications, because maintenance is needed due to changes in resources, resource capabilities, communication methods and standards, communication capabilities, new methods of analysis, and, most importantly, new demands from the customers [W:95M]. Many systems that appeared to have a successful business model initially, have failed because of unaffordable maintenance.
8.7.1 Assigning Maintenance Responsibilities If maintenance is important then loci of maintenance have to be identified in an business organization, and in modules of the information systems that support the business [Landgraf:99]. For instance, in a three-layer mediated system (Figure 3) maintenance tasks are allocated as follows:
a. Source data quality – supplier database, files, or web pages
b. Interface to the source – wrapper, supplier or vendor for supplier
c. Source selection – expert specialist in mediator
d. Source quality assessment – customer input to mediator
e. Semantic interoperation – specialist group providing input to the mediator
f. Consistency and metadata information – mediator service operation or warehouse
g. Informal, pragmatic integration – client services with customer input
h. User presentation formats – client services with customer input
All these areas require maintenance. For a maintenance task one has to identify what are the inputs that can trigger maintenance and who controls the relevance assessment and priority of these tasks. Often maintenance creates new versions, and a requirement to keep older ones available for some time, so that customers can gradually move to new versions and are not sabotaged by service changes. Information about reported problems, planned updates, and actual version changes must be documented in on-line catalogues, so that it is easily accessible when needed.
Most crucial is that all maintenance tasks be assigned, and that the complexity of each maintenance task be limited. Assigning a maintenance task to a group or committee which has conflicting objectives is a recipe for delay, problems, and eventual failure. This rule, `avoid maintenance by committee’, has a direct implication on information systems design, since information systems must be partitionable to match authority assignment for maintenance.
8.7.2 Interface Maintenance A research issue is then defining and understanding the interfaces that are available for the partitioning of information systems. Many of these interfaces are being provided by the various `Open Systems’ consortia. However, many of the contributors are focusing on rapid construction of systems, using resources of their participants. Mapping maintenance tasks to modules and their interfaces should become an inherent aspect for designers of long-lived information systems. Products of information technology must support this aspect by specifying maintenance aspects of their modules, and provide tools and interfaces for maintenance.
8.7.3 Archive Support We presented the problems of accessing historical digital information in Section. 2.4.2. Several solutions exist, all have problems, but information systems should provide convenient and integral support for them.
Convenient copying of potentially valuable information to new media and remote sites for preservation is a fundamental service. This service may be combined with the backup services that are available to industry and also being extended to small businesses and private individuals, who may need such services even more [Backup:99]. Such a business will implicitly deal with media updating, although its focus may not include long-term archival preservation.
Concerns have been expressed that the volume increase will overwhelm our archiving capability [Varon:99]. However, with increasing storage capabilities, distributed services, and some selection the volume should be manageable. A useful function to include would be an automated omission of redundant documents, since customers have little economic incentive to weed out copies themselves [ShivakumarG:96].
Dealing with obsoleting formats is the hardest issue. To preserve contents the original software tool may be used for reading and a more modern tool used for writing when information is copied to new media. In order to perform that task, meta-data is needed that indicates what software was used originally, and maybe even some of the parameters and ancillary files that were used at the time. This information must be bundled together. Some archiving schemes, as UPF and the Dublin Core provide containers for such bundling [Baker:98]. These containers require further tools for access and rewriting.
One cannot be sure that a newer format will faithfully preserve all information from an older format, so that during the process of copying some information may be lost. This is a concern of traditional archivists, who value the preservation of material in its original form. Especially when converting images and sound such concerns are real; a CD does not capture all of the analog contents of a vinyl record.
For digital information, emulation of older computers allows the replay of historical data and program, as long as the bits were faithfully preserved. Now the container should also contain all of the software needed to interpret the contents. However, with this approach the integration of such information with recent data becomes very difficult.
Integration of archiving tools in information systems is an important task. Once the tools exist, backup, archiving, and long-term preservation can be integrated in the workflow that businesses and government use, so that these tasks will be reliably performed, rather than delegated to occasional and irregular processes.
9. Technology Transfer Paths
Transferring results into practice has been a frustrating issue for researchers and their governmental and industrial sponsors. Various approaches have been promoted and subsequently abandoned, often based on single examples and without much thought and analysis. Often the concepts are based on political philosophies rather than on experience. Much more is known about what does not work than what works. Some academic studies analyze technology transfer and report their results to industry and academia [Barr:99].
This section necessarily presents a personal view, and is limited in that sense. I have been lucky to have been able to observe industry, government, and academia for about 40 years, and will try to share here my model and insights. Some of my work has transitioned well, but many other innovations that I have valued highly have been stalled. Much of the funding for my research has come from ARPA (later DARPA) starting in 1958, the year that agency started, complemented by support for general issues in computer science, healthcare applications, and by industrial resources. Crucial to my model, and that of some others, is that there are two types of industries, with different roles in technology transition.
Tool suppliers versus Product Suppliers We assign commercial industries into two categories: tool suppliers (TS) and product suppliers (PS). The tool suppliers (TS) mainly serve the product suppliers (PS) and a few, innovating customers. The PS serve a much broader range of customers, and need a strong consumer market presence. Tools provided by a TS will have less volume, but greater uniqueness and added value per item.
The PSs tend to be larger, and may be an industrial research laboratory within their organization. Most of the personnel in a PS is devoted to production, marketing, and distribution. The TSs tend to be smaller, and have a large fraction of their staff devoted to development, although rarely can invest in research.
The economic benefits and risks differ greatly between TS and PS. Many large companies include divisions dedicated to TS and PS aspects, but their communication, even though internal, is nearly as difficult as communication between autonomous companies engaged in TS and PS. Furthermore, an internal TS group tends to be constrained to serve internal customers, or at least give them priority. At times, successful TS groups have been spun out. Such ventures are considered the best startups with a large angel, as discussed in Section 9.4.3.
In our complex society there are in reality additional layers, where a TS serves as a PS which is in turn a TS to another industrial segment. For the sake of clarity I will ignore multi-level issues here.
9.1 Pre-competitive Development
After fundamental research has developed and validated concepts, ideas that seem worthwhile can be engineered to provide demonstrations and prototypes for testing. Such work, when carried out in the public domain, is termed pre-competitive development. Pressure on research groups to accelerate technology transfer often forces researchers to combine the initial phases with such development.
We consider the scope of a fundamental research project to be on the order of a PhD thesis, say 3 years of an intensive, but part-time effort, with some external advice but little other support. A pre-competitive development project must address all issues surrounding the concept, and requires a much broader effort. Its result should be portable to other sites and computing platforms, usable without the originator sitting at the console, and, if it is an information system, connect to actual data resources. Our estimate, based on a fair number of examples, is that the man-hours required now are 7 times those needed for the fundamental project. The type of effort will differ, so that part of the work is best done by professionals at various levels. Some of the cost increment is due to the need for management. A PhD student or the advisor is often ill prepared for the management task.
Given the substantial differences between research and pre-competitive development it is unclear where the exploitation of open research results is best performed. Since there is still substantial risk, many industries will not be able to take such tasks on. If the researchers are inclined to move into an industrial setting, perhaps by a vision of great riches, then the transfer of research to development can occur by moving people. To gain support, as from an angel or a venture fund, the source research will typically extend beyond the fundamental phase and include some development. Since academic research is limited in time and funding, the depth of the fundamental research for such ventures is likely to be less. We see some conflicts of objectives in achieving a good balance, but having successful ventures spin out of academia has become a new measure of academic success.
Once the venture moves into a company it will become proprietary development. Having the originators in the company setting lessens the need for documentation and hardening of the academic prototype. There may even be a disincentive to full disclosure. The 1 to 7 ratio, mentioned earlier, may now be split differently.
9.2 Integration and Marketing
Depending on the type of product, integration and marketing costs can vary a great deal. Integration costs occur in all those cases where the product does not stand-alone, but has to be integrated into a larger, existing system framework. Examples where integration is hard are in manufacturing and healthcare systems, where there are many existing information and control flows. The cost of integration is often another factor five over the development cost of the hardened prototype. Integration cost will be less where well-developed standards exist and are accepted. For instance, mediation services on the network that deal with HTML documents and their JAVA-enabled browsers are easy to integrate. Information services that access legacy information will require much more work in wrapping those sources. Distribution results into existing channels is even harder.
Marketing costs are easily another factor of two over total development costs. They vary of course by the audience being addressed. If the audience is broad, as all users if the Internet, much shouting is needed to overcome the ambient noise. If the audience is narrow, then marketing can be focused, but will probably have to be intense and knowledgeable about the domain. In those cases the originators will get involved in marketing, since they understand the original concept.
Failures will be frequent, but if the originators are resilient they will have learned a lot, and are often attractive to help in new ventures. A corollary of these observations is that established researchers in secure settings, as universities and especially government laboratories, are less likely to move from their research setting into the wild world of product development. How to transfer their results is more of an open question.
9.3. Problem: Asynchrony
In the discussion above we assumed that the world is ready to embrace the research results as soon as they are produced. But that assumption is optimistic. Many proponents of improved technology transfer advocate strategies to make that happen. However, trying to achieve such synchrony is fraught with dangers [W:95A].
9.3.1 Industry-driven Research A researcher can decide to listen to industry and work on problems that are presented there. However, such a researcher first has to learn about the problem and its setting, get then get adequate support and staff. In many cases a proposal has to be written, approved, and funded. If public funding is involved, the work should be broadly based so that it is non-proprietary. In practice it will be difficult to produce significant research results in less than three years from the time that the problem was identified.
Large-scale industry, typically the product suppliers (PS), takes the lead in identifying problems. They are used to relying on others for products, so that the staff will have to engage in finding resources and initiating contracts. Especially if governmental funding is sought, the effort needed will be greater than most tool supplier (TS) can afford. Establishing governmental funding make also take a few years.
However, industry, once it has recognized a problem, will rarely be able to wait for true research results. Developers in industry, that are close to the problem, are likely to have an adequate solution within 3 to 6 months. Those solutions may not be as elegant as those that a research project may produce, and are likely to be proprietary. However, they are likely to be good enough, well-embedded in its systems, so that subsequent research results are likely to be ignored.
9.3.2 Curiosity-driven Research Many interesting research results have been produced without a defined need. Here no synchrony is expected, but some results will be of interest to industry at some time. Here the initiation time is not a problem. Most researchers will work in their own domain, be familiar with work of their colleagues, avoiding duplication and building on their colleagues results. Awareness of collegial research directions is enhanced by specialized workshops and conferences.
The system works less well when traditional academic boundaries are breached. Relying on the published literature to gain insights into another area, that may have a different research paradigm and perhaps a different ontology, is inadequate. Several intense years may be needed to establish dual academic citizenships.
The traditional means of informing others about such research results has been academic publication. The complexity of modern research, and certainly in computing, means that one criterion of formal publication has been lost: one can no longer count on being able to replicate research results solely from the information in a paper or thesis. Personal contacts are becoming more, rather than less, important in our information society.
Technology transfer is further affected by disintermediation and its effect – unconstrained self-publishing. Loss of specialized librarians makes it difficult for industry to locate available research results. Industry may use web-search engines to search for relevant existing products, but because of firewalls, proprietary publication formats, and semantic mismatches, as summarized in Sections 3.2.8, current search engines are unlikely to pick up related research results.
9.3.3 Fundamental Research We define fundamental research as research that is based on an analysis of conceptual gaps in industrial infrastructures. Defining opportunities for fundamental research also requires industrial input, but that input has to be aggregated and abstracted to isolate lacunae. Both arcs of the industry-research cycle now require thought and analysis. Informally, fundamental research should address problems that industry is likely to encounter when current solution will fail. Likely times to produce results are three to six years after the research direction is defined, it is hard to look further into the future.
Because there were initial industrial contacts, future dissemination may be easier than in the prior approach, although personal contacts may have withered. Semantic mismatch should also be less. The problems faced by industry in accessing fundamental research results are still major.
9.3.4 Transition Windows Work, and especially research, tends to fill up the window of time that is made available for it. There are always opportunities for improvements while the projects is active. Once a academic or industrial research project is completed there is barely time to document and publish the results. Potential customers are unlikely to hear about it before the project window closes. When they do hear about it, the researchers are dispersed, the leaders are working on new projects, the students have graduated, and the demonstrations are no longer operational because hardware and software has been replaced by new versions.
The effect is that in all three research approaches, asynchrony is still a problem. If results are produced before industry is ready, results have to be held. Even where industry performs research internally, getting results to the right people at the right time is hard. The problem has been termed The Silicon Paradox – only large companies spend money on research but cannot exploit innovation. A suggested solution is: don’t decide to commercialize an idea until you understand it as a business opportunity [Liddle:94]. But who can keep the window open?
9.4 Transition Agents
Paper publication was the traditional transition agent, combined with experts that could bridge industry and research groups. People still present the widest bandwidth for moving research into industry. Sometimes such people are the actual researchers, but there is also role for capable observers of research and needs [Dyson:97].
9.4.1 Link Academic Researchers to Industry Since people are an essential complement to research documentation, such linkages can be very effective. Faculty with new ideas have taken academic leaves and initiated major development projects in Silicon Valley. Such moves typically occur when the needs are understood, so that the problem of asynchrony is minimized. Where the projects have been successful, many have not returned to academia. Those that have returned brought new insights and motivations into their research. Liberal leave policies can help here, as well as vesting of retirement funds, so that the risks of a leave are reduced and returning is made convenient. The U.S. Government has an Intergovernmental Personnel Assignment (IPA) program which provides for up to four years leave into governmental service, while pay and status remain at the home institution, which is then reimbursed. Such a policy may be beneficial for leaves to industry. Getting restarted in academy is not easy however, and some participants never return or quit later.
Students who have completed potentially useful research may move as well. However, when moving into a large PS organization they are typically overwhelmed by the established organizational structure. Without strong management commitment and devotion, it is unlikely that their research will transition. When students have moved into a TS, or started a new TS, technology transfer has been much more effective. We will discuss issues for a new TS in Section 9.4.3.
9.4.2 Link Academic and Industrial Research Several governmental programs attempt to link research groups and industry into a single project. Here we have to distinguish again between large PS organizations, who have the resources to participate, but are less likely to able to perform the internal transition, and TS companies, who are unlikely to have the resources.
In the United States, the Small Business Innovative Research (SBIR) mandate, designates a required fraction of most governmental funding programs for small businesses, typically PS types. Working with academics is encouraged, and in some versions required [SBIR:99]. Excessive reliance on SBIR funds, sometimes encouraged by the funding bureaucrats to solve problems they are visualizing, can destroy synchronization to actual industrial needs. Many SBIR projects never matured sufficiently for industrial use. The Esprit model, of forced multi-national cooperation, can also be beneficial for supporting TS transition, if the overhead can be tolerated [ESPRIT:99]. Many PS level organization participate as well, but often the funding only serves short range-industrial needs, leading to the problems outlined in Section 9.3.1.
Other models require funding from the industrial partners [ATP:99]. The concept here is that providing funds shows commitment by the industrial partner. Unfortunately, it is mainly major, PS type companies that can afford the commitment, and as discussed earlier, such commitments, limited to the funds needed for pre-competitive development do not imply subsequent funding for productization and marketing. This problem has been recognized so that industrial participants can provide their share in kind, perhaps by committing staff that is already involved in similar research and development. The rules do not explicitly distinguish TS and PS, often contributing to failure. A PS may lack commitment, and a TS may encounter excessive bureaucracy.
9.4.3 Startup Companies Technological innovation by startup companies has become the most exciting model for technology transfer. The founders are typically motivated by a new concept, either from research or from an industrial development that was not supported in its home organization—often a large PS. These companies are nearly always TSs. Depending on the magnitude of the development needed they may be self-funded, supported by an angel – often a person who has been through a successful startup, or have venture funding. A startup may in fact move through all three phases. If a product of an early phase attracts customers then support for successor phases will be easier.
Asynchrony is a serious problem for TS startups initiated by people with limited industrial background and market support. When research has just been published, few industrial clients will be aware of it. For a PS the adoption of novel technology from an emerging and unknown TS is considered risky. These problems are mitigated where interface standards exist, so that failure of the TS product can be repaired by the PS. Venture funders of a new TS are often aware of the problems and help in management and marketing.
Not all great researchers will be great entrepreneurs. Here is again a role for the funders to participate, and provide complementary human talents. Interpersonal conflicts will arise if the respective roles are not understood or appreciated. People from different backgrounds can work well together if the goals are shared.
The business plan of the TS must also be flexible: if demands for the product are high it is important that resources for appropriate growth are made available, so that the market opportunity is not lost. If the product that the world seems to want, rapid reallocation of resources may be required. If the product appears to be ahead of its time, then a less-intensive, but longer-term support is required. In general a company can present a longer window for technology transition than a research project, as described in Section 9.3.4. In either case, the total expenditures will be greater than with less asynchrony.
9.4.4 Incubator Services Services to help startups are now being provided in many countries. Such incubator services are often sponsored by local governments, trying to attract new industry to their localities, or by large corporations, who wish to stay in touch with research they have supported but cannot commercialize. Universities may participate as well, although their support may be more spiritual than material. Sometimes university and governmental regulations have to be liberalized as well.
The models of incubation support vary. Some focus on a leave model, as discussed in Section 9.4.1 for crucial personnel, others provide space for offices and laboratories at low cost, and others help with management and legal issues. The latter is especially important in surroundings where startups are rare. In Silicon Valley specialists in incorporation and intellectual property use standard procedures, so that non-technical startup costs, both in terms of money and distraction, are minimized. When dealing with inexperienced legal services, these aspects can take years to come to closure.
In practice, startups require a combination of all three: support for people, space, and legal support, in addition to money. A tight collaboration is needed when different support organizations contribute different elements. The intentions may be great, but if a startup has to deal with intersecting rules of governments, universities, and funders, more damage than good may be done. An incubating organization will definitely need strong leadership to shield the developers. How well the concept of incubator services work is till open to analysis.
9.4.5 Research Stores Since asynchrony is such a major problem, we also see a role for research stores. A research store provides a holding service for research that is completed, but has not yet transitioned. This concept was promoted by a director at ARPA, but has seen only limited implementation [Green:92]. A research store should complement a major research program, so that they can have a substantial and focused inventory. It can be funded concurrently with the research, but will have a different funding curve: slow at first, but extending perhaps ten years beyond the research program at a relatively steady level.
The concept of putting research on the shelf until it needed is not simple. It requires more than just collecting papers, for all the reasons that have been presented earlier: search, completeness, etc. Industrial adopters will want to see demonstrations, so that the prototypes that accompany the research outcome must be maintained and transitioned to new versions of hardware and software to remain current. When new interface standards are accepted develop the software most be adapted accordingly. Documentation must be kept up-to-date. In dynamic fields, meanings evolve, and old documentation becomes semantically foggy. The annual cost of such maintenance is easily 10% of the original cost, requiring a considerable financial commitment. If the store holds many research items, the cost per item may be less, and research that has been overtaken can be removed.
We envisage two alternative types of organizations for such support: a specialized commercial company or a governmental organization. We will also cite some other alternatives, which are less clear. In either case the support for the research store must be explicit and long term. The organization also needs to have an internal commitment to technology transfer, so that staff who are carrying such work will be appreciated and rewarded. For those reasons we exclude universities and industrial research laboratories as candidates for having research stores.
Commercial Technology Transfer Company The motivation for a commercial company to take on that role is that there is a real business opportunity in technology transfer. Many small consulting companies are performing technology transfer in an ad hoc manner. Being able to get explicit support for extending their role can be attractive. Industries interested in the research product can be charged, to cover costs and generate profit for the research store.
It is unclear if such companies will be long-lived. They may want to participate actively when commercialization occurs. An active participation should help technology transfer, but may change the outlook and scale of the company. Such a change actually happened in the cited case, but it was abetted by inadequate long term funding of its research store. Still the company grew in 6 years from 10 employees to over 200, and as such may be seen as an example of successful technology transfer.
Governmental Technology Transfer Institute A governmental organization may be ideal for maintaining a research store. In government long term stability is expected and conflicts of interests are reduced. Staffing such a store will require clear mission statements and a flexible policy as the concept matures. Students who have completed interesting research may find good postdoctoral opportunities for a limited a time, allowing them to help move their work into the store and assuring that it works well and can be explained and demonstrated by the permanent staff.
A governmental institute will feel less pressure to sell the contents of their store to industry. Getting industry to pay their share of the transfer costs is also difficult for government agencies. For instance, the CRADA rules that the National Institute of Standards and Technology (NIST) must obey, include a requirement that results must be free to other governmental agencies [ATP:99]. For potential industrial partners such a rule is quite a disincentive, since the government is a major customer, and for some products, as information systems used in planning, the primary one. Charging mechanisms are difficult.
We have also seen instances where governmental institutes missed opportunities because an innovation was declared to be `outside of its scope’. A commercial company is less likely to be risk-adverse, while bureaucrats can only lose by making positive decisions.
Other Candidate Organization Models for Research Stores Other possibilities for technology transfer exist. There are some not-for-profit companies, sometimes spin-offs from university, which could take on a technology transfer role. An example of a non-profit organization involved in some transition is the National Corporation for Research Initiatives (NCRI), started by a former ARPA director [CNRI:99]. Its mission, however, has been research and development management, specifically for Internet technologies, and not specifically technology transfer. Similarly, SRI International, a spin-off from Stanford University, has performed much internal research, but also been supported long-term for the maintenance of Internet technical reports and proposals [SRI:99]. It has performed this service without seeing it as an explicit mission, but the steady external funding has created the needed stability for that niche.
There are a number of laboratories that perform primarily government sponsored research, as INRIA in France, the German GMDs, Rand Corporation and Lincoln Laboratory in the US, and AITEC in Japan, that could take on a technology transfer mission. However, as long as the focus of the organization is primarily research, the technology transfer mission will be accorded a low priority, and not executed as well as it should.
A unique, privately funded organization, Interval, performs research with the specific objective of achieving spin-offs to industrial projects [AllenL:99]. Here the intent is to avoid asynchrony by having realistic business plans for the research projects. To assure a lively research atmosphere and some stability, Interval is committed to a 35% variable workforce and no departmental structure. Research is performed by groups having a finite life span, that can also be disbanded if the original business motivation is found to be invalid. Since individual researchers are members of several (average 2.7) groups, closing out a single group will not frustrate the participants as much. A research project that has been determined to be ahead of its time might well be continued at a low level, obviating the need for a formal research store. How this model will work out is still an open question. Some small consumer businesses have spun off, but have not had a major impact.
9.5 Research Venues and Technology Transfer
We have not discussed where research should take place: at universities, industrial research laboratories, in government-sponsored laboratories, or in government institutes. The major distinction here is the stability of the personnel. Except for senior faculty the turnover of researchers is highest at universities, say 25% annually overall. Government laboratories may have turnover rates of 5% annually. In terms of research productivity the least stable environment has generally outperformed the more stable environment. Some long term research may well be carried out best in a stable setting, but in such a setting the motivation to finish and get commercial results out of the door is weak.
No similar measures exist yet for productivity in terms of technology transfer, and it is likely that the criteria favoring for research productivity may be just opposite from the criteria for technology transfer. If that is true, we have a strong argument for separating research activity and technology transfer activities. Adding money to research budgets and requiring technology transfer from researchers is likely to be a waste, although more research may get done. Assigning technology transition responsibility to researchers as an unreimbursed activity, and motivating them by threatening to withhold further funding if transitions do not take place, is even less economic. Unfortunately, we have seen instances of both tactics.
In terms of developing products it appears that startups do best. Startups do have a high failure rate, about 80%, and many of the remaining startups just muddle along for long times or are bought out at a low price, often to get the customers or the developers, rather than the product. How many failures or buyouts are related to problems of asynchrony is hard to assess, and we have only anecdotal evidence. Most participants in a failed startup are rapidly absorbed by new ventures.
9.6 Summary
Without considering technology transfer as a valuable task with its own criteria, the current muddling is likely to continue. Lack of focus leads to inefficient personnel allocation for this task. Personnel promotion policy keyed to technology transfer success is difficult to achieve in academic, government, or large industrial settings. Universities are likely to assign staff that is no longer effective in research support when required to support technology transfer. Similarly, industry typically assigns people that are not useful for customer-oriented work to deal with technology transfer. Funding should be taken from education or product development.
To be effective, technology transfer has to be the intellectual objective of an organization. The technology transfer organization (TTO) must benefit from successful technology transfer activity and not be viewed as a competitor. Management of a TTO must be able to assess product development timelines so that asynchrony issues are understood and can be made clear to funders and investors. Understanding of trends requires expertise, so that it is best that a TTO has a defined focus, say, information technology. While the investment may be modest, it will take time before financial returns from an investment in pure technology transfer unit can be expected. A TTO unit will need stable base funding, but the stability of personnel resources needs only to be adequate for demonstration to potential recipients. Larger TTOs may engage in further development of their research inventory.
Effective recipients of pre-competitive research will still be primarily small tool builders (TS). That means that even when technology transfer occurs, the income to the TTO will be spread out over some period.
10. Conclusion
We have described the status and changes expected over a wide range of topics related to information technology. However, we could not be comprehensive. Rather than creating long lists of requirements, we have taken representative instances of technology, their sources and consumers, and discussed them in some depth. Many of the governmental reports we are citing produce contain longer lists, a benefit and a liability of committee work.
After identifying unmet needs in the topic areas being discussed, we proposed in Section 8 seven research areas, focusing on innovative software. These are broad, but also not meant to be exclusive. Novel software will require more powerful hardware, but we are confident that hardware-oriented research and development is healthy, and will be able to supply the needed infrastructure. We do believe that most information technology topics we omitted will require similar research and development. The issues of technology transfer discussed apply even more widely than information technology alone.
Acknowledgement
The material for this report came from more published resources than I can list, but even more from discussions with wonderful people that I have encountered in my work and studies. Many concepts came to fruition while on research review or planning committees. If I name anyone, I will feel guilty in leaving out others. For this report I did receive substantial help from Marianne Siroker, who has been organizing the work-related fraction of my life for many years now.
References
Most of these references are to top level reviews and reports, as produced by Scientific working groups and the like, plus some of my personal work. The overall scope of this report is too large to provide a comprehensive list of relevant research and technology. Such entries can then be located indirectly, or through some of the web services, with the caveat that much scientific material is not available directly. Some of it has to be accessed via specialized search systems, as those of the ACM (
http://acm.org/dl) and IEEE (http://www.computer.org/epub/) and much university research is published in formats that are not indexed by the commercial search engines.
[AAAS:99] National Conversation on NSF Advanced Networking Infrastructure Support;
[ACM:99] Neal Coulter, et al: ACM Computing Classification System
http://www.acm.org/class[Adobe:99] Adobe Corporation: PDF and Printing;
http://www.adobe.com/prodindex/postscript/pdf.html[AgarwalKSW:95] Shailesh Agarwal, Arthur M. Keller, Krishna Saraswat, and Gio Wiederhold: Flexible Relations: An Approach for Integrating Data from Multiple, Possibly Inconsistent Databases; Int. Conf. On Data Engineering, IEEE, Taipei, Taiwan, March 1995.
[AllenL:99] Paul Allen and David Liddle: About Interval;
http://www.interval.com, Interval Research Corporation, 1999.[Amazon:99] Amazon Associates Program
http://www.amazon.com/exec/obidos/subst/partners/associates/associates.html[Amico:98] Art museum image consortium (AMICO)
http://www.amico.net/docs/vra[AlbertsP:97] David S. Alberts and Daniel S. Papp (eds): Information Age Anthology, Volume I; ACTIS, National Defense University Press, Washington DC., June 1997;
http://www.ndu.edu/inss/insshp.html[AshishK:97] Naveen Ashish and Craig A. Knoblock: "Semi-automatic Wrapper Generation for Internet Information Sources"; Second IFCIS Conference on Cooperative Information Systems (CoopIS), Charleston, South Carolina, 1997.
[ATP:99] NIST Advanced Technology Program;
http://www.atp.nist.gov/atp/overview.htm[Backup:99] Backup:The #1 Online Backup Service; @backup.com, San Diego CA, 1999,
http://www.atbackup.com[Baker:98] Thomas Baker : "Languages for Dublin Core:"; D-Lib Magazine, 1998,
http://cnri.dlib/december98-baker[Barr:99] Avron Barr: Stanford Computer Industry Project (SCIP)
http://www.stanford.edu/group/scip[BarsalouSKW:91] Thierry Barsalou, Niki Siambela, Arthur M. Keller, and Gio Wiederhold: "Updating Relational Databases Through Object-based Views"; ACM-SIGMOD 91, Boulder CO, May 1991, pages 248-257.
[Behrens:97]. Cliff Behrens: "USDAC’s Prototype Catalog and Data Access System"; Information Technology Workshop 1, Earth & Space Data Computing Division (ESDCD), Code 930, Earth Sciences Directorate NASA/Goddard Space Flight Center Greenbelt MD 20771 USA, http://dlt.gsfc.nasa.gov/itw
[Belady:91] Laszlo A. Belady: "From Software Engineering to Knowledge Engineering: The Shape of the Software Industry in the 1990’s"; International Journal of Software Engineering and Knowledge Engineering, Vol.1 No.1, 1991.
[BeringerTJW:98] Dorothes Beringer, Catherine Tornabene, Pankaj Jain, and Gio Wiederhold: "A Language and System for Composing Autonomous, Heterogeneous and Distributed Megamodules"; DEXA International Workshop on Large-Scale Software Composition, August 98, Vienna, Austria, http://www-db.stanford.edu/CHAIMS/Doc/Papers/index.html.
[BoehmS:92] B. Boehm and B. Scherlis: "Megaprogramming"; Proc. DARPA Software Technology Conference 1992, Los Angeles CA, April 28-30, Meridien Corp., Arlington VA 1992, pp 68-82.
[BonnetT:98] Philippe Bonnet and Anthony Tomasic: "Unavailable Data Sources in Mediator Based Applications"; First International Workshop on Practical Information Mediation and Brokering, and the Commerce of Information on the Internet, Tokyo Japan, September 1998,
http://context.mit.edu/imediat98/paper6/.[BowmanEa:94] C. Mic Bowman, Peter B. Danzig, Darren R. Hardy, Udi Manber and Michael F. Schwartz: The HARVEST Information Discovery and Access System''; Proceedings of the Second International World Wide Web Conference, Chicago, Illinois, October 1994, pp 763--771.
[BranscombEa:97] Lewis Branscomb et al.: The Unpredictable Certainty, Information Infrastructure through 2000; Two volumes: Report and White papers; National Academy Press, 1997.
[BressanG:97] S. Bressan and C. Goh: "Semantic Integration of Disparate Information Sources over the Internet Using Constraints"; Constraint Programming Workshop on Constraints and the Internet, 1997,
http://context.mit.edu/imediat98/paper6/.[PageB:98] Lawrence Page and Sergey Brin: "The Anatomy of a Large-Scale Hypertextual Web Search Engine"; WWW7, The 7th International World Wide Web Conference, Elseviers, April 1998;
http://www7.scu.edu.au/programme/fullpapers/1921/com1921.htm.[Brutzman:97] Don Brutzman: Graphics Internetworking: Bottlenecks and Breakthroughs; Chapter 4 in Clark Dodsworth, jr. (ed): Digital Illusion: Entertaining the Future with High Technology; ACM press, 1997.
[Bush:45] Vannevar Bush: ``As We May Think''; Atlantic Monthly, Vol.176 No.1, 1945, pp.101—108, Section 6;
http://www.press.umich.edu/jep/works/vbush/vbush.shtml, 1997.[Cairncross:97] Frances Cairncross: The Death of Distance; How the Communications Revolution Will Change Our Lives; Harvard Business School Press, 1997.
[CeriF:97] Stefano Ceri and Piero Fratelli: Designing Database Applications with Objects and Rules, The IDEA Methodology; Addison-Wesley, 1997.
[ChangGP:96] Chen-Chuan K. Chang, Hector Garcia-Molina, Andreas Paepcke : Boolean Query Mapping Across Heterogeneous Information Sources ; IEEE Transactions on Knowledge and Data Engineering; Vol.8 no., pp.515-521, Aug., 1996.
[ChavezM:96 ] Anthony Chavez and Pattie Maes: "Kasbah: An Agent Marketplace for Buying and Selling Goods’; First International Conference on the Practical Application of Intelligent Agents and Multi-Agent Technology, London, UK, April 1996.
[ChavezTW:98] Andrea Chavez, Catherine Tornabene, and Gio Wiederhold: "Software Component Licensing Issues: A Primer"; IEEE Software, Vol.15 No.5, Sept-Oct 1998, pp.47-52.
[ChawatheEa:94] S. Chawathe , H. Garcia-Molina , J. Hammer , K. Ireland , Y. Papakonstantinou , J. Ullman , J.Widom: The TSIMMIS Project: Integration of Heterogeneous Information Sources; IPSJ Conference, Tokyo Japan, 1994.
[Chen:76] Peter P.S. Chen: The Entity-Relationship Model --- Toward a Unified View of Data; ACM Transactions on Database Systems, March 1976.
[ChenEa:99] SuShing Chen et al.: NSF Workshop on Data Archival and Information Preservation; Washington DC, March 1999, to appear on cecssrv1.cecs.missouri.edu.
ChoiSW:97] Son-Yong Choi, Dale O. Stahl, and Andrew B. Whinston: The Economics of Electronic Commerce; Macmillan, 1997.
[Cimino:96] J.J. Cimino: "Review paper: coding systems in health care"; Methods of Information in Medicine, Schattauer Verlag, Stuttgart Germany, Vol.35 Nos.4-5, Dec.1996, pp.273-284.
[ClaytonEA:97] Paul Clayton et al.: For The Record, Protecting Electronic Health Care Information; National Academy Press, 1997.
[CNRI:99] Corporation for National Research Initiatives;
http://www.cnri.reston.va.us[Codd:70] E.F. Codd: A Relational Model of Data for Large Shared Data Banks; Comm.ACM, Vol.13 No.6, June 1970.
[ColemanALO:94] Don Coleman, Dan Ash, Bruce Lowther, and Paul Oman: "Using Metrics to Evaluate Software Systems Maintainability"; IEEE Computer, Vol.27 No.8, Aug.1994, pp.44-49.
[ColletHS:91] C. Collet, M. Huhns, and W-M. Shen: ``Resource Integration Using a Large Knowledge Base in CARNOT''; IEEE Computer, Vol.24 No.12, Dec.1991.
[Connolly:97] Dan Connolly (ed.): XML: Principles, Tools, and Techniques; O'Reilly, 1997.
[Culnan:91] Mary J. Culnan: The Lessons of the Lotus MarketPlace: Implications for Consumer Privacy in the 1990’s; CFP’91.
[Cuthbert:99] Adrian Cuthbert: "OpenGIS: Tales from a Small Market Town"; in Vckovski, Brassel, and Schek: Interoperating Geographic Information Systems, Springer LNCS 1580, 1999, pp.17-28.
[CypherST:99] Allen Cypher, David Canfield Smith, Larry Tesler: Visual Interactive Simulations; Stagecraft Software, Inc., Palo Alto, CA; http://www.stagecraft.com, 1999.
[DahlDH:72] O-J. Dahl, E.W. Dijkstra, and C.A.R.Hoare: Structured Programming; Academic Press, 1972.
[DenningM:97] Peter Denning and Bob Metcalfe (eds): Beyond Computation; ACM, 1997.
[diPaolo99] Andy diPaolo: Stanford on Demand; The Stanford Center for Professional Development; http://scpd.stanford.edu/overview/overview.html, 1999.
[Dyson:97] Esther Dyson: Release 2.0: A Design for Living in the Digital Age; Broadway Books, 1997.
[ElMasriW:79] R. ElMasri and G. Wiederhold: Data Model Integration Using the Stuctural Model; ACM SIGMOD Conf. On the Management of Data, May 1979, pp.191-202.
[ESPRIT:99] Esprit, the EU information technologies programme;
[FeigenbaumWRS:95], Edward Feigenbaum, Gio Wiederhold, Elaine Rich, and Michael Harrison: Advanced Software Applications in Japan; Noyes Publications, 1995.
[FlanaganHJK:97] Flanagan, Huang, Jones, and Kerf (eds): Human-Centered Systems: Information, Interactivity, and Intelligence, National Science Foundation, 15 July 1997, pp.218-221.
[FreskoTCM:98]]. Marc Fresko, Ken Tombs, Sue Chamberlain, Patricia Manson: Digital Preservation Guidelines: The State of the Art; study performed for the European Commission, DG XIII-E/4, Applerace Limited, Dec.1998.
[Gates:99] Bill Gates and Collins Hemingway: Business @ the Speed of Thought: Using a Digital Nervous System; Warner Books, 470 pages.
[GennariCAM:98] J. H. Gennari, H. Cheng, R. B. Altman, & M. A. Musen: "Reuse, CORBA, and Knowledge-Based Systems"; Int. J. Human-Computer Sys., Vol.49 No.4, pp.523-546, 1998.Content-Length: 1773
[Gore:99] Al Gore: Proposal of Bill of Rights for Internet Privacy; New York University Commencement Speech, May 1998.
[GravanoGT:94] L. Gravano , H. Garcia-Molina ,and A. Tomasic: "Precision and Recall of GlOSS Estimators for Database Discovery"; Parallel and Distributed Information Systems, 1994.
[Green:92] Brian Green: "Technology on Five Fronts"; Air Force Magazine, Vol.75 No.9, September 1992, pp.62-66.
[Gruber:93] Thomas R.Gruber: A Translation Approach to Portable Ontology Specifications; Knowledge Acquisition, Vol.5 No. 2, pp.199-220, 1993.
[HadjiefthymiadesM:99] Stathes Hadjiefthymiades and Lazaros Merakos: "A Survey of Web Architectures for Wireless Communication Environments"; Computer Networks and ISDN Systems, Vol.28, May 1996, p.1139,
http://www.imag.fr/Multimedia/www5cd/www139/overview.htm.[HafnerL:96] Katie Hafner and Matthew Lyon: Where Wizards Stay Up Late; Simon and Schuster, 1996.
[Hamilton:99] Scott Hamilton: Taking Moore’s Law into the Next Century; IEEE Computer, Jan. 99, pp. 43-48.
[HardwickSRM:96] Martin Hardwick, David Spooner, T. Rando, and KC Morris: "Sharing Manufacturing Information In Virtual Enterprises"; Comm. ACM, Vol.39, No.2, Feb. 1996, pp.46-54.
[Hearst:97] Marty Hearst: "Interfaces for Searching the Web"; in [SA:97].
[HerrmanL:97] Robert Herrmann and Carl Lineberger (eds.): More Than Screen Deep, Toward Every-Citizen Interfaces to the Nation's Information Infrastructure; National Research Council, National Academy Press, 1997.
[Hibbitts:96] Bernard J. Hibbitts : Yesterday Once More, Skeptics, Scribes and the Demise of Law Reviews; Akron Law Review, Vol. 267, Special Issue, 1996; http://www.law.pitt.edu/hibbitts/akron.htm, 1997.
[Hof:99] Robert D.Hof: "What Every CEO Needs To Know About Electronic Business"; Business Week E-Biz, 22 March 1999, pp.2-12.
[Huff:54] Darrel Huff: How to Lie with Statistics; Norton, 1954.
[HumphreysL:93] Betsy Humphreys and Don Lindberg: "The UMLS project : Making the conceptual connection between users and the information they need"; Bulletin of the Medical Library Association, 1993, see also
http://www.lexical.com[Intel:99] The Industry Standard: Intel to Add Personal ID Numbers to Chips, 1/22/99;
http://209.1.23.84/articles/display/0%2C1449%2C3240%2C00.html[JanninkSVW:98] Jan Jannink, Pichai Srinivasan, Danladi Verheijen, and Gio Wiederhold: "Encapsulation and Composition of Ontologies"; Proc. AAAI Workshop on Information Integration, AAAI Summer Conference, Madison WI, July 1998.
[Japan mediation conference]
[JelassiL:96] Th. Jelassi, H.-S. Lai: CitiusNet: The Emergence of a Global Electronic Market, INSEAD, The European Institue of Business Administration, Fontainebleau, France;
http://www.simnet.org/public/programs/capital/96paper/paper3/3.html; Society for Information Management, 1996.[Kahle:97] Brewster Kahle: "Preserving the Internet"; in [SA:97].
[KanamoriU:90] T. Kanamori and M. Ueno: A Fixpoint Semantics for Guarded Horn Clauses"; Institute for New Generation Computer Technology: Fifth generation closure reports, TR0551, ICOT Aprol 1990.
[Kent:99] Robert E. Kent: Ontology Markup Language;
http://wave.eecs.wsu.edu/CKRMI/OML.html, Feb.1999[KentF:99] Stephen Kent and Warwick Ford: Public-Key Infrastructure Working Group;.
http://www.ietf.org/html.charters/pkix-charter.html, 1999.[KetchpelGP:97] Steven P. Ketchpel, Hector Garcia-Molina, Andreas Paepcke : Shopping Models: A Flexible Architecture for Information Commerce; Digital Libraries '97, ACM 1997.
[Kleinrock:94] Leonard Kleinrock (chair): Realizing the Information Future: The Internet and Beyond; Computer Science and Telecommunications Board, National Research Council, National Academy Press, 1994.
[KonopnickiS:98] David Konopnicki and Oded Shmueli: "Information Gathering in the World Wide Web: The W3QL query language and the W3QS System"; ACM TODS, Vol.23 No.4, Dec.1998, pp.369-410.
[LabrouF:94] Y. Labrou and Tim Finin: A Semantics Approach for KQML, a general Purpose Language for Software Agents; Proc. CIKM 94, ACM, 1994.
[Landgraf:99] G. Landgraf: "Evolution of EO/GIS Interoperability; Towards an Integrated Application Infrastructure"; in Vckovski, Brassel, and Schek: Interoperating Geographic Information Systems, Springer LNCS 1580, 1999, pp.29-38.
[Langer:98] Thomas Langer: "MeBro - A Framework for Metadata-Based Information Mediation"; First International Workshop on Practical Information Mediation and Brokering, and the Commerce of Information on the Internet, Tokyo Japan, September 1998,
http://context.mit.edu/imediat98/paper2/[LenatG:90] D. Lenat and R.V. Guha: Building Large Knowledge-Based Systems; Addison-Wesley (Reading MA), 372 pages.
[Lesk:97] Michael Lesk: "Going Digital"; in [SA:97].
[LewisF:99] Ted Lewis and Benjamin Fuller: Fast-Lane Browsers Put the Web on Wheels, IEEE Computer, Jan. 99.
[Lexical:99] Lexical Technology: Oncology Knowledge Authority;
http://www.lexical.com/KS.html[Liddle:94] David E. Liddle, Meg Withgott and Debby Hindus: An Overview of Interval Research Corporation; Human Factors in Computing Systems CHI '94.
[LinR:98] L. Lin and Tore Risch: Querying Continous Time Sequences; Proc. 24 VLDB, NYC NY, Morgan Kaufman, Aug. 1998.
[LockemanEa:97] Peter Lockeman et al.: "The Network as a Global Database: Challenges of Interoperability, Proactivity, Interactiveness, Legacy"; Proc. 23 VLDB, Athens Greece, Morgan Kaufman, Aug. 1997.
[LynchL:96] Daniel C. Lynch and Leslie Lundquist @Cybercash, Inc: Digital Money: The New Era of Internet Commerce; John Wiley and Sons, 1996.
[Lynch:97] Clifford Lynch: "Searching the Internet"; in [SA:97].
[Maes:94] Pattie Maes: Agents that Reduce Work and Information Overload; Comm.ACM, Vol 37 No.7 July 1994, pp.31-40.
[Maney:99] Kevin Maney: Middlemen have nothing to fear, despite scary word; USA Today, 24 Mar.1999.
[Margolis:99] Melanie A. Margolis;
http://www.law.uh.edu/LawCenter/Programs/Health/HLPIHELP/HealthPolicy/980729Unique.htm[MarkMM:99] David Mark et al.: "Geographic Information Science: Critical Issues in an Emerging Cross-Disciplinary Research Domain"; NCGIA, Feb. 1999, http://www.geog.buffalo.edu/ncgia/workshopreport.html.
[Markoff:99] John Markoff: "How Much Privacy Do People Really Need?"; New York Times Service, March, 1999.
[McEwen:74] H.E. McEwen (ed): Management of Data Elements in Information Processing; NTIS, US. Dept.of Commerce pub.74-10700, 1974.
[Melloul BSW:99] Laurence Melloul, Dorothea Beringer, Neal Sample, and Gio Wiederhold: "CPAM, A Protocol for Software Composition", 11th Inter. Conf. on Advanced Information Systems Engineering (CAISE), Heidelberg Germany, Springer LNCS, June 1999.
[Miller:56] G.A. Miller: The Magical Number Seven, Plus or Minus Two: Some Limits on Our Capacity for Processing Information; The Psychological Review, March 1956.
[Miller:93] G. Miller et al.: Five Papers on WordNet; ftp://ftp.cogsci.princeton.edu/pub/wordnet/5papers.ps
[Morningstar:99] Morningstar Investments; http://
www.morningstar.com[Morris:99] Bonnie Rothman Morris: You Want Fries With That Web Site?; The New York Times, 25 Feb.1999, p. D1.
[NaumannLF:99] F.Naumann, U. Leser, J-C. Freytag: "Quality-driven Integration of Heterogeneous Information Sources"; VLDB 99, Morgan-Kaufman, 1999.
[Nelson:74] Ted Nelson: Computer Lib / Dream Machines; 1974; Microsoft Edition, 1987.
[Nelson:97] Ted Nelson: The Future of Information; ASCII Corporation, Tokyo, 1997,
http://www.sfc.keio.ac.jp/~ted/INFUTscans/INFUTscans.html[NTT:99] NTT News Release, June 1998: NTT Develops Secure Public-Key Encryption Scheme;
http://info.ntt.co.jp/mon/98_jun/98jun4.html.[OCLC:99] OCLC: June 1999 Web Statistics; OCLC Research, web characterization project, June 1999, http://www.oclc.org/news/oclc/research/projects/webstats/statistics.htm
[Oudet:97] Bruno Oudet: "Multilingualism and the Internet"; in [SA:97].
[PapazoglouST:99] Mike Papazoglou , Stefano Spaccapietra, and Zahir Tari (eds.): Advances in Object-Oriented Data Modeling; MIT Press, 1999.
[PapowsPM:98] Jeff Papows, Jeffrey P. Papows, David Moschella: Enterprise.Com : Market Leadership in the Information Age; Perseus Books, 1998.
[Perrochon:96] Louis Perrochon: School Goes Internet; Das Buch Fur Mutige Lehrerinnen und Lehrer; in German, Dpunkt Verlag, Heidelberg Germany, 1996.
[PerrochonWB:97] Louis Perrochon, Gio Wiederhold, and Ron Burback: "A Compiler for Composition: CHAIMS"; Fifth International Symposium on Assessment of Software Tools and Technologies (SAST97), Pittsburgh, 3-5 June, IEEE Computer Society, 1997, pp. 44-51.
[Pockley:96] Simon Pockley: "Lest We Forget: The Flight of Ducks"; Conservation On-Line, Stanford University, 1996;
http://www.cinemedia.net/FOD[PonceleonSAPD:98] D. Ponceleon, S. Srinivashan, A. Amir, D. Petkovic, D. Diklic: "Key to Effective Video Retrieval: Effective Cataloguing and Browsing"; Proc.of ACM Multimedia '98 Conference, September 1998.
[PTAC:98] Information Technology Research: Investing in Our Future; Advisory Committee Report to the President;
http://www.ccic.gov/ac/report[RamakrishnanMSW:95] Raghu Ramakrishnan, Hector Garcia-Molina, Avi Silbershatz, Gio Wiederhold (panelists): "Scientific Journals: Extinction or Explosion?"; Proc. VLDB 1995, Zurich, Morgan-Kaufman, 1995.
[RamroopP:99] Steve Ramroop and Richard Pascoe: "Implementation Architecture for A National Data Center"; in Vckovski, Brassel, and Schek: Interoperating Geographic Information Systems, Springer LNCS 1580, 1999, pp.65-74.
[Richards:99] Justin Richards: Evolution and Revolution in the User Interface;
http://www.ibm.com/ibm/hci/guidelines/design/realthings/ch4s0.html[Resnick:97] Paul Resnick "Filtering Information on the Internet"; in [SA:97].
[Rhodes:97] Bradley J. Rhodes: "The Wearable Remembrance Agent, A System for Augmented Memory"; Proceedings of The First International Symposium on Wearable Computers (ISWC '97), Cambridge, Mass, October 1997, pp. 123-128.
http://rhodes.www.media.mit.edu/people/rhodes/Papers/wear-ra.html[Rindfleisch:97] Thomas C. Rindfleisch: "Privacy, Information Technology, and Health Care;" Comm. ACM; Vol.40 No. 8 , Aug.1997, pp.92-100.
[RodriguezEa98] Juan A. Rodriguez-Aguilar, Francisco J. Martin, Pablo Noriega, Pere Garcia, and Carles Sierra: "Towards a Test-bed for Trading Agents in Electronic Auction Markets"; AI Communications, ECAI, Vol.111 No.1 August 1998, pp. 5-19..
[Rothenberg:96] Jeff Rothenberg: "Metadata to Support Data Quality and Longevity"; First IEEE Metadata Conference, April 1996, http://www.computer.org/conferen/meta96/rothenberg_paper/ieee.data-quality.html
[RumbleEa:95] John Rumble (convenor), Committee on Application of Expert Systems to Making Materials Selection During Design: Computer-Aided Materials Selection During Structural Design; National Materials Advisory Board, National Research Council, NAMB-467, National Academy Press, Washington DC 1995.
[RussellG:91] G. T. Russell, Deborah , Gangemi Sr.: Computer Security Basics; O'Reilly & Associates, Inc., 1991.
[SA:97] Scientific American Editors: The Internet: Fulfilling the Promise; Scientific American March 1997.
[SBIR:99] The National SBIR Program Resource Center;
http://www.zyn.com/sbir/sbres[ShannonW:48] C.E. Shannon and W.Weaver: The Mathematical Theory of Computation;1948, reprinted by The Un.Illinois Press, 1962.
[ShardanandM:93] U. Shardanand and Pattie Maes: "Social Information Filitering: Algorithms for Automating Word of Mouth"; CHI 93, ACM and IEEE, Denver CO, 1993.
[ShivakumarG:96] N. Shivakumar and H. Garcia-Molina: Building a Scalable and Accurate Copy Detection Mechanism ; DL '96 Proceedings, ACM, 1996.
[SilberschatzSU:95] Avi Silberschatz, Mike Stonebraker, and Jeff Ullman : Database Research: Achievements and Opportunities into the 21st Century, Report of an NSF Workshop on the Future of Database Systems Research, May 26--27, 1995; Sigmod Record, ACM, 1995.
[Simons:98] Barbara Simons: "Outlawing Technology"; CACM, Vol. 41 No.10, Oct 1998, pp 17-18.
[Singh:98] Narinder Singh: "Unifying Heterogeneous Information Models"; CACM, Vol.41 No.5, May 1998, pp.37-44
..[Snodgrass:95] Richard T. Snodgrass (editor): The TSQL2 Temporal Query Language; Kluwer Academic Publishers, 1995.
[SRI:99] Stanford Research Institute: Internet Requests for Comments,
http://www-mpl.sri.com/rfc.html[Stefik:96] Mark Stefik: Internet Dreams, Archetypes, Myths, and Metaphors; MIT Press, 1996.
[Stefik:97] Mark Stefik: "Trusted Systems"; in [SA:97].
[Stix:97] Gary Stix: "Finding Pictures"; in [SA:97].
[Stoll:96] Clifford Stoll: Silicon Snake Oil : Second Thoughts on the Information Highway; Anchor Books 1996.
[Sweeney:97] L. Sweeney. Guaranteeing anonymity when sharing medical data, the DATAFLY system. AMIA Proceedings, Journal of the American Medical Informatics Association, Washington, DC, 1997.
[Turk:98] Matthew Turk(chair): Workshop on Perceptual User Interfaces (PUI); San Francisco CA, Nov.1998,
http://www.research.microsoft.com/PUIworkshop.[TuttleEa:98] Mark S. Tuttle, N.E.Olson, K.D. Keck, W.G. Cole, M.S. Erlbaum, D.D. Sherertz, C.G.Chute, P.L. Elkin, G.E.Atkin, B.H.Kaihoi, C. Safran, D. Rind, and V. Law: "Metaphrase: An Aid to the Clinical Conceptualization and Formalization of Patient Problems in Healthcare Enterprises"; Methods Inf Med 1998; Vol.37 No.4-5, pp:373-383.
[USAToday:99] USAToday, 1999: Archive retrieval;
http://archives.usatoday.com.[Varon:99] Elana Varon: Storage Dilemma Looms; Federal Computer Week, January 25, 1999.
http://www.fcw.com/pubs/fcw/1999/0125/fcw-newsstorage-1-25-99.html[VernonLP:94] Mary Vernon, Edward Lazowska, Stewart Personick: R&D for the NII, Technical Challenges; Conference report, 28 Feb.1994 , EDUCOM, Washington DC, 20036.
[WangWF:98] Wang, James Ze, Jia Li, Gio Wiederhold, Oscar Firschein: "System for Classifying Objectionable Websites"; Proceedings of the 5th International Workshop on Interactive Distributed Multimedia Systems and Telecommunication Services (IDMS'98), Plagemann and Goebel (eds.), Oslo, Norway, 113-124, Springer-Verlag LNCS 1483, September 1998;
http://www-db.stanford.edu/~wangz/project/imscreen/IDMS98.
[WangWL:98] James Z. Wang,, Gio Wiederhold, and Jia Li: "Wavelet-based Progressive Transmission and Security Filtering for Medical Image Distribution"; in Stephen Wong (ed.): Medical Image Databases; Kluwer publishers, 1998, pp.303-324.
[Weiser:93] Mark Weiser: "Some computer science issues in ubiquitous computing"; Comm.ACM, Vol.36 No.7, July 1993, pp.74-83..
[Widom:95] Jennifer Widom: "Research Problems in Data Warehousing"; Proceedings of the 4th Int'l Conference on Information and Knowledge Management (CIKM), ACM, November 1995.
[W:86] Gio Wiederhold: "Views, Objects, and Databases"; IEEE Computer, Vol.19 No.12, December 1986, pages 37-44.
[W:91]Wiederhold, Gio: "The Roles of Artificial Intelligence in Information Systems"; in Ras (ed): Methodologies for Intelligent Systems, Lecture Notes in Artificial Intelligence, Springer Verlag, 1991, pp. 38-51.
[W:92] Gio Wiederhold, Gio: "Mediators in the Architecture of Future Information Systems"; IEEE Computer, March 1992, pages 38-49; reprinted in Huhns and Singh: Readings in Agents; Morgan Kaufmann, October, 1997, pp.185-196.
[WJL:93] [WiederholdJL:93] Gio Wiederhold, Sushil Jajodia, and Witold Litwin: Integrating Temporal Data in a Heterogenous Environment; in Tansel, Clifford, Gadia, Jajodia, Segiv, Snodgrass: Temporal Databases Theory, Design and Implementation; Benjamin Cummins Publishing, 1993, pp. 563-579.
[WC:94] Wiederhold, Gio, and Stephen Cross: "Alternatives for Constructing Computing Systems"; in Yamada, Kambayashi, and Ohta: Computers as Our Better Partners, ACM Japan Symposium, World Scientific Book Co., March 1994, pages 14-21. Japanese translation by Yahiko Kambayashi in Computer to Ningen no Kyousei, Corona publishing, Tokyo Japan, 1994, pp. 283-295.
[W:95A] Wiederhold, Gio: "Dealing with Asynchrony in Technology Transfer"; in P.Apers, M.Bouzeghoub, and G.Gardarin: Advances in Database Technology -- EDBT'95; Lecture Notes in Computer Science, vol.1057, Springer Verlag 1996, pp. 631-634.
[W:95M] Gio Wiederhold: "Modeling and System Maintenance"; in Papazoglou: OOER'95: Object-Oriented and Entity Relationship Modelling; Springer Lecture Notes in Computer Science, Vol. 1021, 1995, pp. 1-20.
[WBSQ:96] Wiederhold, Gio, Michel Bilello, Vatsala Sarathy, and XioaLei Qian: "Protecting Collaboration"; Proceedings of the NISSC'96 National Information Systems Security Conference, Baltimore MD, Oct. 1996, pp.561-569.
[W:97H] Gio Wiederhold: "Effective Information Transfer for Health Care: Quality versus Quantity"; in Lewis Branscomb et al.: The Unpredictable Certainty, Information Infrastructure through 2000; Volume 2: National Academy Press, 1997, pp. 553-559.
[W:97M] Gio Wiederhold: "Customer Models for Effective Presentation of Information"; Position Paper, Flanagan, Huang, Jones, Kerf (eds): Human-Centered Systems: Information, Interactivity, and Intelligence, National Science Foundation, July 1997, pp.218-221.
[WG:97] Gio Wiederhold and Michael Genesereth: "The Conceptual Basis for Mediation Services"; IEEE Expert, Intelligent Systems and their Applications, Vol.12 No.5, Sep-Oct.1997.
[W:98D] Gio Wiederhold: "Weaving Data into Information"; Database Programming and Design; Freeman pubs, Sept. 1998.
[W:98P] Gio Wiederhold: "On Software Components: A New Paradigm"; Int. Workshop on Component-based Electronic Commerce, The Fisher Center for Management and Information Technology, U.C. Berkeley, July 1998, Section 5.
[WJG:98] Gio Wiederhold, Rushan Jiang, and Hector Garcia-Molina: "An Interface Language for Projecting Alternatives in Decision-Making"; Proc. 1998 AFCEA Database Colloquium, AFCEA and SAIC, San Diego, Sep. 1998, http://www-db.stanford.edu/LIC/SimQL.html
[W:99] Gio Wiederhold: "Information Systems that Really Support Decision-making"; in Ras et al., Proc. 11th International Symposium on Methodologies for Intelligent Systems (ISMIS), Warsaw Poland, Springer LNCS/LNAI, June 1999.
[W:OO] Gio Wiederhold: Foreword for Papazoglou, Stefano Spaccapietra, and Zahir Tari (eds.): Advances in Object-Oriented Data Modeling; MIT Press, 2000.
[Winograd:97] Terry Winograd.: "The Design of Interaction"; in Peter Denning and Bob Metcalfe (eds.), Beyond Calculation, The Next 50 Years of Computing, Springer-Verlag, 1997, pp. 149-162.
[Wulf:94] William Wulf (chair): Information Technology in the Service Society; Computer Science and Telecommuncations Board, National Research Council, 1994.
[ZelenikFS:97] Robert C. Zeleznik, Andrew S. Forsberg and Paul S. Strauss: "Two Pointer Input for 3D Interaction" , ACM SIGGRAPH, April 1997, pp. 115-120.
.