Wiederhold (Part D): Database design, file structures, indexing, and hashing methods.
Database D, Basic 15 minutes
B.1 Database Design: (10 minutes)
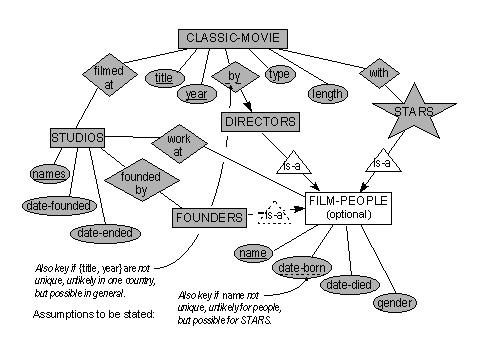
You have been requested to design a database for fans of old movies. Searches may occur by movie title, director, studio, or star and should be able to retrieve related information. We use UPPER-CASE here for the entity names; Capitalized attributes can have multiple entries. Titles are not unique.
MOVIES have as attributes {title, year, director, Studios, type, length, Stars).
DIRECTORS and STARS have attributes as (name, date-born, date-died, gender, Studios).
STUDIOS have (names, date-founded, date-ended, Founder).
1.a Diagram (4 minutes)
Draw an E-R (not an ODL) diagram for your design.
1.b Keys (2 minutes)
Identify the keys in the diagram by underlining them. State any assumption you make.
1.b Relations (4 minutes)
List the relational, normalized schema for the design of your E-R diagram.
B.2. Performance (4 minutes)
The relation planned for the year 2000 census will have about 600 million (6*10^8) records of 1000 bytes, stored on 6000 byte blocks (transcription error made it 4000). Fields in the record include the respondents’ Primary Occupation (PO) in a 52 byte field and their Congressional District (CD) in a 4 byte field.
You need two indexes, one for the CD and on for the PO.
In the computations, disregard details as differences of bytes and digits and space needed for items as block headers and the like. If you need other specifications, make and justify reasonable assumptions.
2.a Number of index entries (1 minute total)
2.a.1 How many first level index entries will be need for the indexes on the PO?
2.a.2 How many first level index entries will be need for the indexes on the CD?
2.b Number of levels (3 minutes total)
For that many indexes we will always want a multilevel or a B-tree index. Chose either
and state your choice:_______________ . Rough calculations are acceptable, but show clearly what they are.
2.b.1 How many levels will the index for the PO have?
2.b.2 How many levels will the index for the DC have?
B.3 Culture (1 minute)
Why did it take about 15 years between the publication of the relational model in 1970 before commercially viable large relational databases were in common use?
Wiederhold (Part D): Database design, file structures, indexing, and hashing methods.
Database D, Advanced
A.1 Database Design 1. (5 minutes)
The historians developing the database for the fans (Question B.1) also desire an additional relation: REMAKES which links link derived movies to their original. It is to include a number indicating how much the derived movie took from the original (ranging from 0.1 to 0.9).
1.a Define the attributes for this relation. (1 minute)
1.b Write a query in a suitable query language to list all ancestors of the 1990 film by Avildsen ‘ROCKY IV’. (2 minutes)
1.c Will a query of this type always terminate? (1 minute)
If yes, state the reason why.
If no, add a constraint that will cause it to terminate
A.2 Database Design 2 (5 minutes)
You are a consultant working with groups of users in a company manufacturing household appliances. There is an inventory of parts used to assemble the appliances.
The people in Purchasing tell you that inventory items should be organized by supplier.
The people in Assembly tell you that inventory items should be organized according
to the item being assembled., say toasters, electric teapots, washing machines, and the like.
2.a Sketch a design that satisfies all groups in the form of an E-R diagram. (2 minutes)
2.b Show the corresponding relational schema. Define some key attributes, but don't worry about all the detailed data attributes. (3 minutes)
A.3 Index Design (6 minutes)
For the census problem of question B.2, given that all the data has been collected:
3.a Index choice (1 minute)
What type of multi-level index did or would you choose, and now explain why?
3.b Index processing (3 minutes)
You are told that queries on combination as Salary-class and County are frequent.
These are also fields in the census database, and their indexes are 3-levels deep.
There are 20 Salary-classes and 2000 Counties. Indicate how you process those
queries with the given indexes (show up to 10 major steps).
3.c Specify an access structure specific for this type of query and compare its
expected performance (2 minutes)
3.d Does your solution generalize, i.e., deal with the many fields in the census
database? (1 minute)
If yes, say why.
If not, say why.
A.4 Spatial database (3 minutes)
You have a database containing counties, i.e., regions of the country, defined by lists of boundary vertices (x, y points). You need to find in which county a post-office is located, given by its x,y coordinates. No other data are available. Sketch a fast process for obtaining the answer.
A.5.. Hashing versus Indexing (3 minutes)
5.a When is hashing preferred over indexing? Give one reason. (1 minute)
5.b When is hashing worse than indexing? Give two reasons. (2 minute)
A.6 Hashing Design (5 minutes)
Design a hashing scheme for a file with at most 100 000 employees. Employee records are 10 000 characters in length. The input to the scheme is the 9-digit social security number, which is unique for all employees.
6.a What are considerations for determining the bucket size? (1 minute)
6.b What are considerations for determining the number of buckets? (1 minute)
6.c Provide a reasonable hashing function. (3 minute)
6.d Will your hashing scheme create any collisions? (1 minute)
If Yes, say why.
If not, say why.
A.7 Database Optimization (3 minutes)
To reliably estimate performance we should know how many records will correspond to a query.
7.a What is a common assumption, when no other information is available, for the number of records corresponding to an index term? (1 minute)
7.b What kind of information can be collected to improve the estimates of the number of records. Discuss the benefits and costs of maintaining such information. (2 minutes)
---------------------------------------------------------------------------------------------------------------
Solutions, Basic Part
B.1 Database Design
B.1.a E-R diagram
B.1.b Making different assumption leads to different key designations, but they should match. See keys in diagram above and relations below. There have been a bunch of movies with the same title, and even some with the same title and same director. In general, there are many people with the same names, even a few actors have had the same name, but they were of different generations.
B.1.c Relations
MOVIES (title, year, director, type, length).
FILM-PEOPLE (name, date-born, date-died, gender)
[Avoids repeating attributes for DIRECTORS, STARS, and even FOUNDERS]
DIRECTORS (name, date-born) , STARS (name, date-born) .
STUDIOS have (names, date-founded, date-ended)
FOUNDERS (names, name, date-born) . [ names only if Founders are unique]
filmed-at (title, year, names)
by (title, year, name)
with (title, year, name)
work-at (name, names)
founded-by (names, name) [Only if Founders are not unique]
B.2. Performance
The relation planned for the year 2000 census will have about 600 million (6*108) records of 1000 bytes, stored on 6000 byte blocks. You need two indexes, one for the Congressional District (4 bytes) and on for the primary occupation (52 bytes).
B.2.a: You need in each case (6*108 / (6000/1000) ) = 108 (100 million) index entries.
((6*108 / (4000/1000) ) = 1.5 * 108 is ok too, but the solution assumes the original value)
The block numbers must hence have 8 digits or bytes. We assume here bytes.
Simplest choice: For a multi-level index you have to access 100 million index entries.
B.2.a.1 For the PO the index entries are 60 bytes, and 100 entries fit into a block.
The number of levels is then log 100 108 = 4 exactly.
(Or, incrementally: the first level will then require (108 / 100) = 106 = 1 000 000 blocks, so that the second level will need that many index entries, requiring 10 000 blocks.The third level (106 /100) = 104) = 10 000 index entries, requiring 100 blocks. The final, fourth level needs (104 /100) = 100 index entries and fits in one block exactly.)
B.2.a.2 For the CD index the entries are 12 bytes, and 500 entries fit into a block.
The number of levels is then log 500 108 = 2.97 ~ 3.
(Or, incrementally: the first level will then require (108 / 500) = 2*105 = 200 000 blocks, the second level will need that many index entries, requiring (2*105 / 500) = 400 blocks .The third level has 400 index entries and requires only one partially filled block . )
Alternate choice: For a B-tree index the blocks will contain fewer entries because extra space is left to simplify updating (50% after a split, 75% average after many insertions, 67% average after insertions and deletions, we use here a 67% density)
You still have to access 100 million index entries, but they will require now
100 000 000/.67 = 150 million index slots and the block numbers must now hence have 9 digits or bytes. We again use the byte/digit assumption here.
B.2.a.1’ For the PO the index entries are now 61 bytes, and 98 entries fit into a block, but only 0.67 * 98 = 65 slots will be used.
The number of levels is then log 65 108 = 4.42 ~ 5.
(Or, incrementally the first level will then require (108 / 65) = 1 540 000 blocks, so that the second level will need that many index entries.
The third level must hold (1 540 000 /65) = 24 000 index entries, the fourth level gets (24 000 /65) = 355 index entries, a fifth level needs 355/65 =6 blocks, and the final, sixth, level needs again only one, very sparse block.
B.2.a.2’ For the CD index entries are 13 bytes, and 461 entries fit into a block, but only 461 *0.67 = 309 slots are used.
The number of levels is then log 309 108 = 3.22 ~ 4.
(Or, incrementally the first level will then require (108 / 306) = 33 000 blocks, so that the second level will need that many index entries. The third level requires (33 000 / 309) = 1 060 index entries, and the final, fourth, level needs (1 060 / 309) four blocks.
B.3 It took a long time before the required optimizations could be developed.
Earlier database systems had structures, as hierarchies and networks, that, when programmed by experts, allowed quite fast access to the data.
Solutions, D, Advanced Part
A.1 Database Design 1. (5 minutes)
1.a REMAKES {newtitle, newdirector, newyear, oldtitle, olddirector, oldyear, fraction}
where {newtitle, newdirector, newyear, oldtitle} is the key, with the assumption that no director makes a movie with the same title in one year, but that a movie can have multiple (fractional) ancestors. Other assumption, if clearly stated, are also acceptable.
1.b Write a query in a suitable query language to list all ancestors of the 1990 film by Avildsen ‘ROCKY IV’. (2 minutes)
SELECT * INTO found FROM REMAKES past, REMAKES now, found
WHERE now.newtitle = ‘ROCKY IV’
AND now.newdirector = 'Avild
AND now.newyear = 1990.
AND found.oldtitle = past.newtitle /* recursion */
AND found.olddirector = past.newdirector
AND found.oldyear = past.newyear .
1.c Will a query of this type always terminate? (a thought question)
YES: since a remake is always later than the original, so that no cycles can occur.
NO, since a remake could be in the same year and databases can (will) have errors.
Add constraints: AND new.newyear > new.oldyear
A.2 Database Design
A.2.a,b Diagram
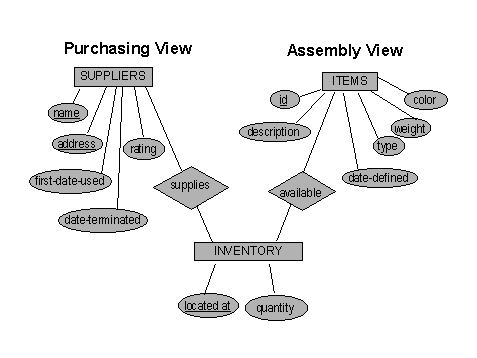
Instead of making the Inventory explicit, it could just be modeled as an E-R many-to-many connection, but that would be harder to explain to the customers.
A.2.c Relational Schema
SUPPLIERS (name, address, first-date-used, date-terminated, rating)
ITEM (id, description, date-defined, type, weight, color)
INVENTORY (id, name, location, quantity)
[Assumption - same stuff is not all in one place]
A.3 INDEX design
A.3.a Once collected, the census data is stable, so the faster and dense multi-level index is preferred over a B-tree index.
A.3.b. Counties partitions better than Salary-classes so first
Step 1. Obtain index for county
Step 2 Find index entry for desired county, say = "San Mateo'.
Expect (6*108 / 2000) = 3*105 entries, and several thousand low-level index blocks, depending on field size for county and possible prefix-compression.
Step 3. Retrieve all records. Will still access nearly 3*105 blocks since it will be rare that two records are in the same block.
Step 4. Filter the records obtained for salary-class. If salary-classes are of equal size obtain (3*105 / 20) = 15 * 103 records.
Step 5. Output the 15 * 103 = 15 000 records.
The alternative, pointer intersection for County and Salary-class, is not effective, since
There will be (6*108 / 20) = 3*107 pointers for the Salary-class attribute, more volume than the records obtained in Step 3, and then the actual records must still be obtained.
A.3.c. Create a multi-attribute index combining Counties and Salary-class, say, CountySalary. That will have 2000 * 20 = 40 000 choices and partitions the file better than either single-attribute index.
Step 1. Obtain index for CountySalary
Step 2 Find index entry for desired combination, say = "San Mateo10".
Expect (6*108 / 40 000) = 15 *103 entries, and still about a thousand low-level index blocks, depending on field size for CountySalary .
Step 3. Retrieve all records. 15 * 103 records.
Step 4. Output the 15 * 103 = 15 000 records.
A.3.d Generalization for multiple attribute indexes. Assume that the census file might have 100 attributes.
Yes, it generalizes conceptually. One could even create combinations of3, 4, attributes, until the product of their selectivities = ~ 1.
No, creating all combinations would require a very large number of indexes, and about 10 000 indexes to create and maintain.
A.4 Spatial Search.
First find all the enclosing boxes for the maximal and minimal values of all vertices relative to the post offices, then filter counties obtained by computing position relative to lines between adjoining vertices.
A.5 Hashing verus Indexing.
Hashing is better for unique attributes, since fewer accesses are needed,
Indexing is better for non-unique attributes, where hashing le
A.6 Hashing Design
A.6.a For large files best to have large buckets, at least of page size. Buckets should hold multiple records, so that a few collisions in a bucket don't create overflow.
Having bigger buckets does not reduce access time much, and increases internal search time. With 10 000 byte records may want 100 000 byte buckets
A.6.b Buckets should be partially filled to keep overflow rare.
So the number of buckets (b) should be about 1.2 (or more) * filesize / pagesize.
A prime number for the number of buckets is best, but it should be at least not a multiple of 2, 10, or other low integers used frequently. Here place 8 records/bucket, and have 100 000/8 =~ 12 500 buckets, but use 12 503 buckets to avoid poor multiples.
A.6.c address = v mod b = SSN mod 12 503 works fine with the considerations for b given above.
A.6.d Any hashing scheme will create collisions, that's the principle. Only if the source is guaranteed unique and the hash function does not alter it, would collisions be avoided.
A.7 Database Optimization
A.7.a The common assumption is that data are uniformly distributed, i.e., that every distinct attribute value is equally likely to occur. This is rare in practice, the most natural distribution is Zipfian.
A.7.b To provide better information about the selectivity for a particular attribute value a distribution can be kept. Attributes then are sorted into bins according to their actual frequency of occurrence. The frequencies can not be assumed to follow the index sort sequence, so that a separate structure is typically required. Update can be continuous or periodic, say overnight. If the size is excessive, only extremely frequent values may be kept explicitly, for instance those occurring in 5% or more of the records, since in those cases a sequential scan is preferable over using an index.
-----------