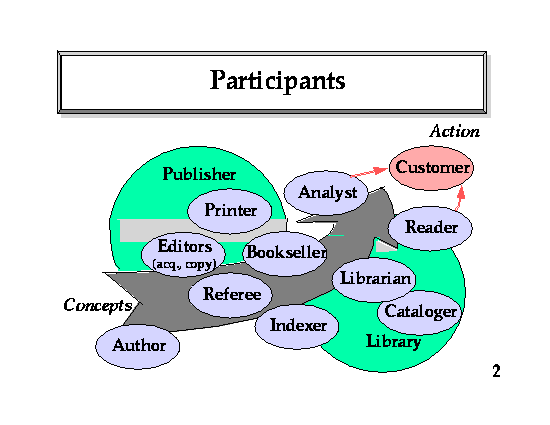
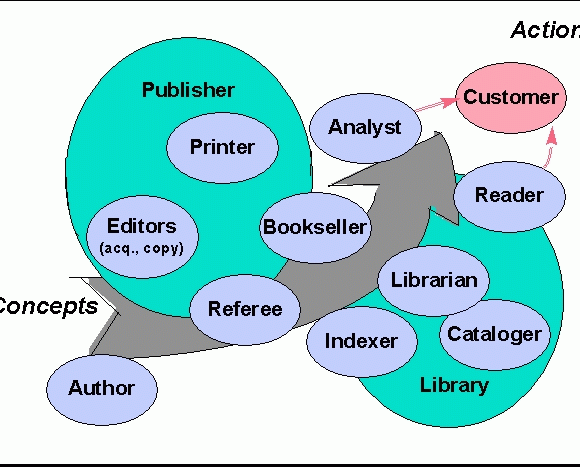
 Figure Library participants
Figure Library participants
Why do you rob libraries, publishers and authors? Because that's where the information is. [modern corrolary of Wille Sutton's reason for robbing banks]
 Previous chapter: Entertainment and education -
Previous chapter: Entertainment and education -
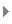 Next chapter: Healthcare
Next chapter: Healthcare
Figure Library participants
As the redistribution of functions in the digital libraries takes place, each participant has to consider what their information product is apart from its physical manifestation, i.e., what added information value is generated by their efforts. An author, while viewed as primarily being creative, also depends greatly on abstracting and reformulating earlier work, especially in scientific areas. An editor makes the work of a good author accessible, and filters out poor work. A publisher advances money to an author, enabling more rapid generation of material, employs reviewers to help with selecting authors' submissions, hires editors, and invests in typesetting, printing, and inventory. Critics assess new publications, and disseminate their judgements to a wide audience. The booksellers focus on market understanding, distribution and provide a pleasant environment that encourages people to browse.
In 1901 the Library of Congress (LoC) started printing its cards, and made copies available to other libaries, providing a consistent basis for the majority of new !!local information publications !!!!huh>>>. Onto the LoC cards specific local information was typed, and sometimes useful observations by the librarians. Over the years complex cataloging rules have emerged: "Rule Interpretations".(RI) issued for U.S. librarians by the LoC. Examples of rules for alphabetization appear in [Knuth:73]. The paper card catalogues grew at increasing rates, and as more people used them, became increasingly awkward, as well as targets for vandalism. In the 1960's the LoC devised a format for computerizing catalog entries, and started creating Machine Readable Cataloging (MARC) records. By the end of the decade most other libraries found that they could not keep up with cataloging their new acquisitions, and started using the MARC records for their own books, just adding some retrieval and perhaps purchase or gift information. The MARC-linked records use the LoC provided ISBN number so that books can be mechanically cross referenced among all libraries. About 8M MARC records have been produced.
In 1968 the Ohio College Library Center (OCLC), and its successor, the Online Computer Library Center started printing MARC cards using computers. OCLC cards are slightly more expensive, but can be delivered sorted according to many criteria, reducing labor for the libraries. When member librararies acquired new books they could check online, for a modest fee, if there was a pre-existing MARC or OCLC record, and save the effort to make a new a completely new catalog record according to the LoC RI. If no prior reference existed, or if the record was inadequate, the librarian could create a new catalog record, and receive a credit. The distributed nature of updating, however, meant that the quality of entry varied so that, for instance, many author's names, especially foreign ones, appear inconsistently, making it hard to assure thorough *recall. We encounter such inconsistencies in other efforts using networks, and will present technology addressing such problems in the Chapter on MEDIATOR Technologies.
Subsequently !year! OCLC started providing a retrospective conversion service (RETROCON) to libraries which converts their older paper catalog card data to computer records as well. Through these processes it created a huge database of catalog information. By 1994 the OCLC database contained nearly 30M entries. Local shelving data is now added to the online OCLC records. However, most supplemental information from specific cards is lost, except from a few libraries (The New York Public Library, Harvard) who microfilmed their cards before shipping them to OCLC.
Today many card catalogues are gone and the cabinets are being recycled. In 1993 the University in Berkeley replaced its catalog, superseded by its MELVYN system, by eight study tables.
Most libraries put only entries to entire works, as books, into their catalogs. When an entire year's worth of a serial journal has appeared, the journals will be bound and indexed as new volume of the serial title. That approach is fine for management of the holdings on the shelves of a library, but does little to help an individual researcher who is interested in a specific topic. A journal volume contains a wide range of articles within a scientific area, the articles will not be in any meaningful sequence, so that without further assistance entire volumes must be browsed to find relevant information.
Creation of an index to topics contained in serial volumes provides the needed assistance for researchers. Such an index is not easy to construct. Authors should follow the terminology established by their predecessors, but when they move into new areas, invent their own terms. When topics merge, use of terms becomes inconsistent. New terms are often essential to make crucial distinctions in domain or applicability, but also isolate work from work of others that may be similar in result, even though different in approach. To help readers locate all relevant materials * thesauri can be constructed that place the terms used into a hierarchy so that a researcher can use a more general term to locate more specific material indexed under their own terms. The * vocabulary for access is now controlled. A controlled vocabulary also helps in resolving with simple confusions in word usage, as * synonyms, where two words have been used to denote the same concept, and overloading, where a term means two different things based on context, as shown in Figure: Disambiguation
Figure:
Synonyms and terms requiring disambiguation.
Within a domain, say woodworking, there should be no ambiguity, but when the domain is unknown, or when discourse covers multiple domains, then disambiguation is often needed. When we have a bishop who enjoys woodworking, then the term miter is ambiguous.
Indexing of published articles using a thesaurus requires understanding the domain. To train indexers in using the MEdical Subject Headings (MESH) thesaurus requires !!6 months!! and to remain certified a MESH indexer participates annually in a !!3 week!!> update course. Since science, and scientific terminology changes the ongoing certification enables the MESH thesaurus to be updated as needed.
The indexing of every article in a large number (!n=?) of medical journals provides a very high added value to the users of NLM resources and a sound basis for ongoing research. Duplication of research effort is minimized, results can be rapidly accessed by a broad community, and, when errors are published, that information is also rapidly disseminated. The technical means of dissemination is of course a computer network. Initially NLM operated its own network, with terminals in the libraries of many medical schools in the country (MEDLINE). As computer capabilities increased MEDLINE was improved, so that now also abstracts for most of the indexed articles are available on-line Today more and more access to MEDLINE is provided through Internet, although the primary MEDLINE interface is oriented towards expert librarians, and hard to use casually.
!also MeSHT , Index Medicus T. MEDLARS T, The National Network of Libraries in Medicine (NN/LM T), TOXNET T, DOCLINE T
To make the entire contents of the articles available requires overcoming several barriers:
the volume of material is significantly larger, probably beyond the capacity of the mainframe technology
now used for MEDLINE, the inclusion of formulas and figures would require the adoption of standards for
their transmission, and, last but not least, the management of copyrights for the journals and their authors.
We address copyright issues later, and now focus on tools for
authors.
The National Library of Medicine has sponsored a major effort to unify medical terminologies
The outcome of this research is UMLS, described in the Chapter on
HEALTH-CARE
Like any ontology, UMLS requires long-term knowledge maintenance. It is now updated annually, but
quarterly updates are contemplated. Some of the changes needed are to correct errors and omissions, but
others will acount for the *evolution in the use of the terms. The existence and utilization of a sharable
ontology brings the community and its use of terms together through practice. The latter is probably the
most important result in the long run. By having tools more people will share concepts and naturally evolve
towards common meanings for terms, just like the Kings James Bible provided a major impetus towards a
consistent spelling in the !!16th?? century. The focus of UMLS research is indeed now the development of
applications, to obtain user coherence and feedback. As such UMLS, in its domain, is a good precedent
setter for HPCC and the general effort to establish highways of the future. The medical domain does have
the advantage that its participants are well-educated and demanding of high quality services. Since
healthcare delivery is costly, even relatively modest benefits can have a high financial impact.
However, *timesharing systems in academic settings were already adapting *teletypewriters to their needs.
Later models teletypewriters and other electric typewriters were able to print text in lower case. The
character sets of these typewriters and printers both were limited to less than 120 letters and symbols, and
only one font type and size was available without physically changing printing heads. Boldface printing had
to be imitated by printing the same characters twice, without advancing the paper.
Printing based on *Xerography, eventually controlled by lasers, provided the flexibilty needed for attractive
documents. *Laser printing was also pioneered in the 1970's at XEROX *PARC, who had the technological
resources to innovate in document production. Soon other companies with expertise in making copiers
entered the field. Today there are also printer mechanisms based on *inkjets that provide high-quality
output at somewhat lower cost and speed. Since they can squirt inks of several colors they are popular for
pretty presentations. For black-and-white printing laser-printing dominates.
to be embedded
The TeX language uses *macros to assemble its primitive commands into easy to use commands for
document preparation. An example of \TeX macro use and its output is shown in Fig.\tex, the
corresponding macro definition is shown below in Fig. Texmacro..
A popular default collection of TeX macros, LATEX, was established by Leslie Lamport of SRI
International. Donald Knuth donated his rights to TeX to the American Mathematical Society (AMS),
which today expects all manuscripts to be supplied in TeX format. Other academic *publishers, even those
that focus on computing, as the *ACM and *IEEE, are still struggling with electronic submission of
manuscripts, trying to follow the leadership of the mathematicians. This an example where a group of users
with a valid need and leadership were empowered by technology, while the technologists fell behind.
Today TeX is available for nearly any combination of computer, operating system, and printer. Processing a
source document through TeX creates a file in a * device-independent format (.DVI). Today .DVI format is
most often translated for printers that have * Postcript (.PS) capabilities. Postscript is a commercial *
standard, marketed by Adobe, which was derived from earlier work in high-quality word-processing at *
PARC.
Unfortunately, web browsers do not routinely accept TeX as input. A proposal for HTML 3.0 did include a
useful subset, but has not been implemented. Until this lacunae is remedied, it remains difficult to present
mathematical text directly in web pages. The best solution available today (1998) is for the author to
procees TeX into Postscipt form, and for the reader to obtain a plugin for the browser that can
handle postscript, such as Ghostscript.
The limits are now largely overcome. Authoring tools as Microsoft Word, Wordperfect, etc. are
WYSIWYG systems. However, when their output is exported to Web pages as HTML, they have to cede
the specific formatting to the browser, so that the results only approximate `What You saw'.
Today computer storage, processing capacity, transmission, and presentation of literary text exceeds greatly
what is possible without computers. The entry of pre-existing documents remains tedious, however most
current works are prepared using computers. so that recent material can made available.

Figure: A query issued
to Medline for an papers of interest. (not yet in)
>

Figure: Smoking: An illustration of negative feedback in a chain of causal relationships(not yet in)
smoking � increased blood pressure � heart attack �
reduction of smoking
A total of 15 other thesauri and vocabularies contributed information to UMLS. Major, active sources are
the * LoC list of Subject Headings (LCSH), and * MEDLINE, * MeSH T.
!also used were AI/RHEUM, Physicians Data Query (PDQ), DXplain, Quick Medical Reference (QMR),
Dorland's Illustrated Medical Dictionary, Online Mendelian Inheritance In Man (OMIM), ICD9-CM LIBRARY.History.printing
Proper presentation of results is nearly as important as the contents. Around 1965 the first high-capacity
computer printers appeared which could print both upper- and * lower-case, removing one barrier from the
acceptance of computers for the production of literary works. But these printers were costly and slower, and
rarely used. I recall an argument from the early 1970's where I was told that the computed results I
presented were faked, since a computer `could not produce text in lower case'.LIBRARY.History.TEX
Around 197x Donald Knuth learned that the publisher of his epic series "The Art of Computer
Programming" [Knuth73], Addison-Wesley, was discarding hot lead linotype equipment in favor of photo-
typesetting, and could no longer set mathematical formulas as beautifully as before. There is, of course, no
fundamental reason for a reduction in quality due to the use of computers, and Prof. Knuth proceded to
learn what made books and type beautiful and to create software that allowed computers to do the same. His
Metafont and TeX software revolutionized the production of mathematical and
academic works [ref]. Authors could now specify typefaces and document layout in exquisite detail, or let
*default choices take over, which embodied standard conventions and simplified document preparation.
Figure An example of \TeX as written by an author and its
result in print. (not yet in) LIBRARY.History.WYSIWYG
A disadvantage for a casual author in using TeX is that a manuscript in TeX form does not look on the
screen as it will be presented in print, as shown above in Figure TeX. Much
preferable is an authoring environment where * `What-You-See-Is-What-You-Get' (WYSIWYG,
pronounced "wizzy-wig"). Early WYSIWYG approaches were hindered by lack of processing capabilities
and storage of their computers, so that formats and typefaces were quite limited. It was easy to tell when a
document was prepared by a computer. The output may be legible, some cute fonts were included, but in
general the results were ugly. LIBRARY.Functions
The functions of a library are to acquire works, store them, make the works available to the reader, and
reimburse the author and the publisher for their efforts. We discuss these four functions for a Digital Libary
now, building on the support functions presented in earlier chapters. An important, informal mode of
accessing digital information, by *browsing, was covered as
Browsing.Functions.browsing .
When we discuss libraries here, we consider the entire process of getting information from concept to the reader. Building libraries on the Information Highways will affect all phases of the publication path.
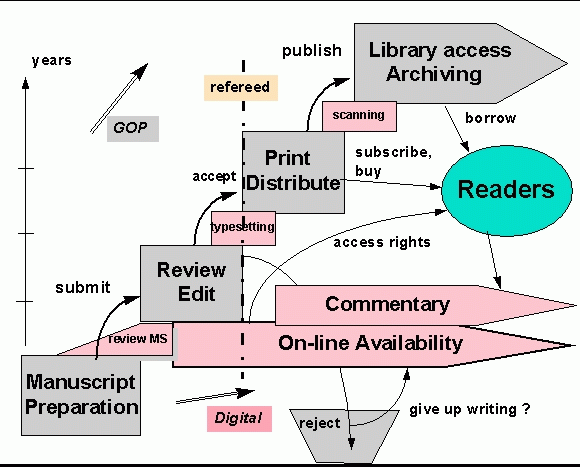
Two important metrics are used in library science: *relevance and *precision. Relevance indicates how much of what is retrieved by a query is of interest and benefit to the searcher. Precision indicates how few relevant documents have been missed by the searcher. These metrics are interdependent. If the system presents all documents`it has than the desired material is certainly included, the relevance is high, but the precision is low. A system which presents a single relevant documents has a high precision.
An efficient represention for text is * character encoding. A sequence of 7 bits can represent 1^7 = 128 symbols. The common * ASCII standard uses 7 bits to represent 95 printing characters, the remainder are available for control and checking purposes. While 95 characters comfortably cover the alphabet, digits, and punctuation, it limits literary and scientific expression. Since most character transmission today is in terms of 8-bit units, * bytes, more symbols (up to 2^8=256) can be represented in a byte-sized character. However, no 8-bit * standard has been widely adopted, so that common non-ASCII characters in DOS, the Apple Macintosh, UNIX-based systems, and in much word-processing software are differently represented. In Japan 16-bit representations are used for * Kanji (Chinese-based) symbols. A five- and six- digit * telegraph code is sometimes used in China, where a larger set of symbols is needed.
Using more bits per character does not address the general problem found in a library. The works in a library use a variety of fonts, underlining, subscripts, mathematical symbols, Chinese ideographs, right-to- left writing, and the like. The solution is to use * embedded commands, consisting of sequences of control and printing characters to indicate changes of font, font size, spacing, and characters beyond the defined ASCII set, but again, no general standard exists. In Section \L\T\TEX you can find some examples of embedded commands. TeX uses the character '\backslash' as a control character to prefix its commands, as seen in Fig. TeX.
Transforming published text from its printed pages into ASCII is tedious and error-prone. The paper sheets have to be placed on a * scanner and the scanned image has to be analyzed to obtain ASCII. If the text contains unusual characters, equations, tables, drawings, photographs, or handwriting, the limits of automated analysis are soon reached, although ongoing research is steadily increasing the flexibility and capacity of *optical character recognition and reducing the error rate.
When character recognition is not feasible, the scanned images can be directly stored in the digital library. Now, however, there is no indexable material, so that ancilliary information has to be attached to each image so that it can be retrieved. Finding a page by content is much more powereful than by attribute, as shown in Fig. Associate.

Figure Querying a
Digital Library a) by Content and b) by Attribute. (not yet)
Most modern writing is done using computer systems, so that scanning and optical character recognition are not needed. However, most *word-processing software packages have their own conventions for controlling layout, font changes, and the like. Layout standards are starting to take hold, the Structured Graphical Markup Language (SGML) is introduced in Section LIBRARY.Technology.SGML below. A language for representing text of publishable quality is TeX, as described in Section LIBRARY.Technology.TeX, but it is not the only candidate for preparing material for publishing. The user-friendliness of * What-you- see-is-what-you-get (WYSIWYG) interfaces for word-processing hides internal complexities from authors, but also reduces the need for internal consistency. When WYSIWYG documents enter digital libaries considerable conversion and editing may be needed to achieve make the contents of the library consistent in form. Inconsistencies hinder search and further processing.
Pictures and graphs are poorly integrated in most text-processing systems. Pictures scanned into a computer system are aquired as *digital images. They are often *compressed to save space. Some images are created by digital technology, as Computer-Aided Tomography (CAT) for medical diagnosis, and handled similarily. The capability of optical and related systems is increasing rapidly, with better resolution, i.e., more *pixels, and more resolution, i.e., more bits per pixel. Images used by intelligence agencies can require nearly 1 Gigabyte each, or 3000 times as much storage as a TV image. Compression, as was presented in ENTEDU.Technologies.compression can reduce this volume drastically, but also requires the integration of compression software.
Graphics produced on a computer can be captured by recording the sequence of commands that created them. Engineering drawings, mainly generated by interaction with computer, are stored according to graphical standards, which reduce the drawing to a collection of lines and curves, each described by their location in thedrawing and some attributes, as thickness, curvature, color, and the like. We present the emerging technologies in ENTENDU.Multimedia .
Eventually the problems of acquisition of old, printed material will be minor. Most past works will have been entered and be stored somewhere, as now is being accomplished with library catalogs. Nearly all new material is produced digitally, and problems to be faced will be compliance with standards and protection of intellectual property when no paper master copies exist.
Intellectual Property: A Cross-National Perspective [David Arulanantham] \L\F\STORAGE A major function of any library is storage of its contents and the indexes needed to access its contents. Storage capacities of computers ave been increasing so rapidly that storage was not even deemed to be crucial issue in the HPCC technology initiatives. Still, the digital library must be concerned about storage, especially if it acquires much existing material in image form.
Storing the content of a page in image form requires approximately 1 Megabyte of storage prior to compression, about three times that amount if it is in color. This estimate is greatly affected by higher resolution, needed for fine print and mathematics, and levels of greyscale. Acquisition or conversion of material into character-encoded form (ASCII) greatly reduces its bulk, and also permits automation in indexing, retrieval analysis, and processing of literary material. Indexes permit rapid access to selected, relevant documents in large collections. Indexes, and the tools to use them, represent the value added by a library, and can make use of library effective even for works stored in one's own studio. Comprehensive indexes can be large, often equaling in size the volume of the documents themselves.
Digital indexes must be processable to be effective, and hence should be never stored in image form. Indexes can refer to data in text or in multimedia forms, as images, video clips, or voice clips. The reference format must adapt itself to the type of the work. For text a filename, and page and character range are fine. It is more awkward to refer to part of an image. In video or voice clips a temporal range must be indicated. Indexes need not be stored with the documents they refer to, and their maintenance differs considerably from document maintenance. When documents in an electronic library combine text and other material, the text is often stored in a more accessible location, and other material, as images, is retrieved by a reference from the text.
In Chapter ENTEDU we presented video for entertainment and education. In that setting transmission is bundled by broadcasting the same material to many people at the same time and rate. In information retrieval bundling is very undesirable, since every reader has to be able to proceed at their own speed.
FIND AU Find a document by name of author FIND TI Find a document by title FIND SU Find a document by subject FIND TO Find a document by topic, presupposes a thesaurus DISPLAY what's found HELPFigure: Ccl: Main commands of the Common Command Language.

Figure
Vectorspaces !!from Salton if possible!!
It is a small step to move to *dynamic books, where a skeleton designating the desired chapter are predefined, but the actual chapters are obtained from digital resources when needed. The chapters would be latest versions, and convey the most-up-to-date knowledge. Some smarts will be required to assure consistency. A cross reference to a chapter that is not included can be satisfied later, unless that chapter is subsequently deleted. If the referenced chapter has been revised, the intended reference may be confusing. Including *timestamps with such cross-references can help, and permit going back to past versions of the chapter that should have been archived. Avoiding this problem, by inhibiting updates of referenced material, would disable the up-to-dateness that dynamic books contribute over paper books. The table-of- contents and the index can include all candidate chapters. The bibliography may only collect entries of chapters`that have actually been obtained.
Unless the reader controls the entire composition of a dynamic book, there are now two levels of authors:
Non-academic authors do depend on their income from selling their works, directly or indirectly. If their work is part their employment, their employers may have the right to it. Owners can sell their work for one- time use, for unlimited use, or for exclusive use. Publishers who obtain such works can similarly resell rights obtained from authors. Readers can freely use the information conveyed in literary works, but not redistribute the material in its fixed form.
In the U.S. protection for intellectual property (IP), as defined in copyright and patent law derives from the constitution:
Since 1968 copyright for an author in the U.S. is established as soon as it is fixed, that is committed to paper or electronic media. To simplify protection of literary works, copyrights can be registered with the U.S. Copyright office, by supplying a simple claim form and two copies of the work [1976 Copyright Act]. For complex works it is adequate if only part of the work is submitted; the submission should be sufficient to disambiguate eventual conflicts. Violations of copyright require that the offended party bring their claims forward as a legal suit. Having the work registered helps in bringing a claim, but is not essential.
The copyright laws spell out conditions for reuse of literary works. Recognized are rights for cases of
To enforce copyright while transporting or storing electronic documents encryption may be used. Decryption key must be distributed with care, as described in the Chapter on Security.
The access limitations to digital works, established for the LoC by the Information Industries Association (IIA), the National Federation of Abstracting and Information Services (FAIS), and the Association of American Publishers (AAP) with the LoC !!disable implementation of the concept of digital libraries.
The public performance of a work, traditionally applied to music and plays, has broad implications in digital libraries. It not only covers broadcast of music, but also the execution of a copyrighted computer program. A person who obtains a program legitimately, obtains a copy of the work fixed in some digital storage medium for personal use, but not necessarily the right to its use as a performance, say, as part of a for-profit service. Useful services along the digital highways require obtaining multiple rights. An information service emulating a library will require having rights to the documents it can retrieve, or a method for reimbursing the owner of their copyright, as well the rights to the performance of programs which provide the retrieval service. If the programs use some domain or expert knowledge, as is often provided by librarians or other experts, then that knowledge may be protected by its own copyright.
Much early work in digital library technology was carried out in scientific or governmental laboratories where copyright issues were easily ignored. Many such systems exist, and will grow and continue to provide important services. At the same time, future digital libraries will need to incorporate technologies that support reimbursement of producers of information. Without such mechanisms much useful information will be withheld from public use, and the creation of high-quality, new information will be stunted. We present a rights system which is testing concepts that are emerging to deal with digital recordation and reimbursement for use of copyrighted material.
[[Material to be edited ]]
[Kahn at HPC:If copyright getting registration easy, will be there overload, No central deposit is needed.
Distributed but secure. Today deliverer has liability - shipping a book by federal express. Also cable TV
programs incorporating. Digital object is equivlant package and program, Most our use is copies of
performance = display.
Putting on the net is performance?? ]
TimeOnLine: supply taste and put it in paper for convenience
[digital objects` identified by RSA fingeprint]
Bob Kahn 6Apr95
Intellectual property is crucial.
Tole of patent copyright Interfaces can be both copyrighted and patented - does on
supesede the other?
"The congress shall hace the Power... to promote the progress of Science and useful Arts
by securing for limited times to Authors and Inventors the exclusive Right to their
respective Writings and Discoveries.
Works are copyrighted, fixed. Can flow around. Duality in Kahns view waves vs
particles. Protected in tangible and intangible form
Copyright protection architure. IETF sponsor. Allow owners to negotiate terms and conditions "Money is not made from information, but from validating ownership" Architecture is minimal see cnri web server. has also software for local naming authority. http://www.cnri.reston.va.us Global services identified now by IETF Naming authority is local global/local //global/local or >>global>naming get digiatl objects (handle) give handle get metadata handle is close, but not an URN When sombody left"re cpyright ... [[end of materail to be edited - into technology section?]]
Processing of images, or *image understanding (IU) is a crucial topic for dealing with the volume of images that is arriving in the warehouses along the digital highways. We only summarize the phases, so that readers can recognize when they encounter writings on the topic where the work falls, since no complete paths exist today.
The issue of *precision, i.e., missing relevant images altogether is not easy to assess. The effort to check an entire large image library is beyond reason today, so that precision cannot be evaluated outside of modest samples. The quality of image processing software can be assessed by placing artificially relevant images in the library and checking that these are retrieved.
!!!!expand> IU: spec: planning (feature selection (easy->finer) ((features (brightness, clustering into regions (size shape) mutual arrangemnents) testing searcher evaluation refinemnet>
There is success with specialized documents, using metamodels Military messages K-10 reports from businesses to tabular form Price Waterhouse, using SOAR Problem summaries from medical records? Morning report [Zdonik]
Also work on financial articles from the Wall Street Journal using templates !!Check dup>
Work at Xerox PARC
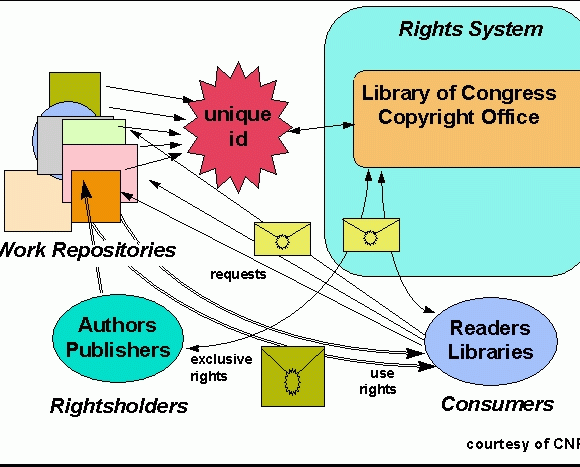
The rights and payment conventions are being stressed by electronic acquisition and dissemination. An ongoing effort by the Corporation for National Research Initiatives (CNRI) in cooperation with the LoC is defining the architecture for an Electronic Copyrights and Permissions Management System (ECMS). The participants in such a system are the rights holders, the works being protected, and the requestors. Works will need unique identifiers, and standard notations for various types of uses will need to evolve. By formulating rules and fees the rightsholders will be able to assign their processing to an ECMS. Secure transmission of rights will be needed to protect the works and the reimbursements. The actual works are stored outside of the ECMS, on any repository that affords sufficient protection. Figure Architecture for Rights sketches the linkages among the participants and system components.
Automation of rights management should greatly reduce the time needed to get permissions, and mitigate a major motivation for infringing on copyright protection. Automation can also reduce the costs, and bring them in line with fees that encourage compliance with copyright laws. Smaller rightsholders will be able to participate in a shared, automated ECMS, removing yet another incentive for authors to deal with traditional publishers.
Refining queries !!\X?>
| Aspect | Digital Library | Database | | |
|---|---|---|---|
| ------------ | ------------------------------- | ------------------------------- | | |
| Content | Processed *Information | Observed Facts, i.e., Data | | |
| Source | Authors, editors, publishers | Clerks, Data acquisition devices | | |
| User | People (students, ...) | Analysis Programs | | |
| Validation | Expert editors | Validation Programs | | |
| Dissemination | By assignment of rights | Via proprietary services | | |
| ------------ | ------------------------------- | ------------------------------- | | |
!Grateful MED
If the digital highways had existed at that time <1978> he might not have wanted to leave Columbia, MO.
<
There will still be the underserved, for whom the free libraries provided relief in the past. People who live
far from the main information highways now pay high access charges, in the form of rural telephone tolls,
which can be more to reach the nearest town than the price of an interstate connection. In the 1930's the
"Rural Electrification Service Administration (REA) helped bring light and appliances to every farm. Its
bureaucracy still exists in the Department of Agriculture and spends over \dol140M per year. It might find a
justification for its existence in repeating its success in the next century in disseminating information rather
than power to rural communities.
The publishing enterprise will experience the greatest disruption. Its members will only be able to survive if
they learn to focus on the value they are providing, and those values are likely to be domain specific as well
[Lederberg:92]. Responding to calls for more scientific information by increasing the number of
publications, raising the prices of the journals because of low subscription rates for these publications,
causing libraries financial distress, which in turn forces many libraries to cancel subscriptions, has intiated a
viscous spiral where in the end only a few paper copies will be sold, and the remaining distribution will be
by copying and interlibrary loan. Interlibrary loan is also simplified through the use of networks
[Dutcher:89]. In this swamp independent digital library services may flourish.
Commercial publications, supported mainly by advertising revenue, will feel the pinch from other
directions. Some advertisement revenue is already flowing today to the few cable shopping channels. When
these services become interactive, allowing customers to browse through domains of interests, ask specific
questions on, say, quality, from an independent source, see demonstrations on-line and the like, as presented
in Chap.\F., then their revenues will be severely impacted. The only advertisers that may remain are
perfumes, with their printed odor-strips, for which I have not yet seen a digital replacement.
LIBRARY.Lists
LIBRARY.Lists.resources
We can only display a sampler of collections made available by digital libraries
today, and even if we were complete at one point, we'd be out-of-date a week later. Any comprehensive list
should be kept on-line, as a high-level library service itself. Maintaining such a listing will be another
valued-added service, and deserving of financial reimbursement. A current, free resource reference is the
sourcebook on digital libraries, compiled by Edward Fox [Fox93].
To get information about NASA data, you can use MOSAIC. From the NASA home page -> GSFC page ->
psace data and computing Division->
research onDigital Library Technologt, with examples for Browsing
name owner / address content charging size [ref] | %source
AVFRR NASA Goddard / cjtucker@gfscmazil.nasa.gov Land and ocean emissions
obtained by the advanced very high resolution radiometer free |
Ball Aerospace Earth images / 1 meter resolution commercial planned
for 19xx [Bill mark]|
Compustat company business, stock data subscription [Goh:94] |
CNRI Consortium for National Research Initiatives Internet conventions, rightsmodel
private non-profit, grants [www.cnri.reston.va.us] |
CRSP company business, stock data subscription [Goh:94] |
DataStar Knight-Ridder / Europe, Miami FL bibliographic super service |
Datastream company business, stock data subscription [Goh:94] |
defense conversion Pasha Publications / Arlington VA 800 952-0122 , 800 227 8431
|
Dialog Knight-Ridder / Palo Alto CA, Miami FL bibliographic super service / 450
databases subscription +/ fees |
Disclosure company business, stock data subscription [Goh:94] |
DoD TRP Defense Conversion Clearinghouse technology transition projects 1 800
352-2949 orinternet |
DVMS Ziff Information Services / Medford MA |
Edgar Securities and Exchange Commisssion company business, stock data
subscription [Goh:94] |
Einstein NASA Space and planetary observations free |
Electronic Book Technology Providence RI SGML viewers |
Envirotext DoE Un.Illinois, Champaign Library of environmental information
|
Equinet Knight-Ridder / Australia, Miami FL financial info.service subscription
|
ExPASy Hospital Cantonal / Geneva Switzerland Molecular Protein Biology /
electrophoresis images with links from spots to data WWW |
Eyeglass Earth images and processing / commercial
planned |
Fortune 2000 U.S. company business, stock data subscription [Goh:94] |
GDE systems, Orbital Sciences, Litton Earth images / 1 meter resolution
commercial licensed, planned for 19xx |
GOES NASA Images from Geostationary Earth Observations Sattelite |
IRAS Caltech /wheelock@ipac.caltech.edu Infrared Sky Survey atlas on-line
|
Landsat EROS / NASA Earth observations cost/free subsets |
Lockheed Space Imaging Earth images and processing / 1 meter resolution
commercial licensed, planned for 1997? [Bill mark]|
LEXUS MeadData Central / Columbus OH? legal reference service |
NEXUS MeadData Central / Columbus OH? bibliographic super service |
OASIIS Western Atlas Software / Houston TX geographic data |
PDS Jet Propulsion lab / pds_operator@jplpds.nasa.gov Mars digital image map
free |
Regnet NPR planned governmental regulations |
Reuters Great Britain company business, stock data subscription [Goh:94] |
SMMR NASA Cloud, polar ice, snow etc.radiation data from scanning multichannel
microwave radiometer |
SPOT Spot / France Earth images / 10 meter resolution * 54km commercial
operational |
SSM/I NASA hydrology data from special sensor microwave imager |
TIROS NOAA Television infrared observing sattelite |
TOVS NOAA-NASA Sea and earth altidudes from Operationl vertical sounder |
TOMS NOAA Total Ozone Mapping spectrometer |
Visible Human NLM Atlas providing 3-D cross-sections of a human being
[Ackerman:94] there should be a better reference |
Worldscope company business, stock data subscription [Goh:94] |
Worldview WorldView Corp Earth images / 3 meter resolution commercial
licensed 1993 / planned for 19xx |
Yellow Pages Prodigy business phone numbers, NY, New England free |
Fin
Previous chapter: Entertainment and education -
Next chapter: Healthcare  List of all
Chapters.
List of all
Chapters.
CS99I  CS99I home page.
CS99I home page.
NOTES
-------
ARPS Meeting 25Nov 94
Needed services
Discobvery seraching
data intercghnage and Format conversion
Authentication and security
electronc paymnets
Linkage
Repository 500 years
Registration and publishing
----------
Missining abstarctio again
-
Digital Library and electronic commerce mutually support each other.
micro payments
Barry diller quote Nov 24th "we have overhyped the Information Highways"
John Young "Let's do experimnts"
Commercenet has secure Mosaic