prepared for IFIP Working Group on Database 8th Working Conference on
Database Semantics (DS-8) in Rotorua, New Zealand, DS-8
Stanford University
Stanford CA, 94305, U.S.A.
{gio, jan}@db.stanford.edu
Abstract
The semantics of diverse sources are captured by their ontologies, the collection of terms and their relationships as used in the domain of discourse for the source. When sources are to be related we rely on their ontologies to make the linkages. The traditional task of builders of ontologies has been define a single ordered structure for the domain terminology, in the form of a tree or lattice. Applying ontologies to multiple applications leads to ever larger ontologies. Unfortunatly, defining a single ontology for the universe is not only a daunting, but an infeasible task.
The SC (Scalable Knowledge Composition) approach we present here is to defer the task of globally classifying terms and relationships. Instead, we focus on composing ontologies for use as needed. We define contexts to be our unit of encapsulation for ontologies, and use a rule-based algebra to compose novel ontological structures.
Composition of ontologies allows us to create ontologies for applications as needed. Creating a sound algebra encompassing the required operation also allows manipulation and composition of the process. The knowledge required for composition is seen as being held and maintained by an application support specialist. Scalability becomes a dynamic concept, rather than one which focuses on growing the number of rules and concept frames. But composition of independent, specialized ontologies also makes the issue of semantic mismatch explicit. Our algebra has hence to support rules that resolve mismatches dynamically. Once these rules exist we can reuse them, and achieve maintainability of the resulting system. Although our project is relatively young, we will show some examples where composition can achieve results that would not be feasible in massive systems.
Introduction
There is growing need for a formal management of semantics. As our information systems grow, and become accessible to wider audiences, the question of what does a statement really mean becomes crucial. Within a closeknit group the terms used are well understood because they refer to real objects in our neighborhood or are abstractions built from other known terms [Roy:97]. However, when disjoint groups merge ontologies the meaning of these terms loses their context, and can differ significantly [SchuylerHTS:93]. More insidious is actually when terms from distinct contexts differ slightly. Then the differences may not be easily observed, and only when computations give erroneous results will the misunderstandings be discovered. For instance, maps prepared for property assessment will use different identifiers than the terms used in giving driving directions. When the directions prove inadequate, say because of a road closure, the map is needed, and matching points have to be found. A term as crossing refers to road intersections when driving, but to type intersections (road, stream) on a property map. Another example of such a semantic difference is the use of the term employee, which in payroll system includes all persons being paid, and in a personnel system includes all people available to do work. In a realistic and large organizations there are nearly always some people that do not fall into both categories: staff taking early retirement, employees on loan to outside projects, specialists on consulting contacts, etc.
We see hence a need to manage and compose ontologies to satisfy many practical applications. This issue is broader than just the multimedia aspect, but since multimedia typically come from distinct sources and have not been required to interoperate until recently, the issues are particularly acute. We expect to never see a single, well-maintained, universal ontology, but rather to have articulations [Guha:91] among ontologies that allow correct interoperation of diverse domains, each with their own contexts [McCrthy:93]. The operational result is the same, but we believe that our approach is both maintainable and scalable.
To compute and exploit the articulations requires expertise as well. We hence have a partitioned view of the knowledge required to create and exploit ontologies. There are the domain experts, providing ontologies and processing rules for their sources, and the articulation experts, who understand what useful concepts appear in these source domains and understand on how to combine them in order to support applications. There can be many more of these application supporting contexts than source contexts. These derived contexts can be composed as well, following the capabilities of our algebra.
Definitions
Since we are concerned in this paper about well-defined terms it behooves us to first define our terms. Central to our model for dealing with semantic mismatch are the following concepts
We will clarify these definitions throughout this paper, but note already that this definitions are only assumed to be valid in the context of our research, and we do not claim that these definitions are universal. We note that each context is associated with a body of expertise. Figure 1 relates the major defined concepts to each other.
Figure 1: Concepts of the SKC approach
The paper continues with a discussion of related work, and then describes our use of these concepts and our methodology for composing contexts. Then, we examine a theoretical framework within which to express our technique. Finally, we discuss the role of our rule-based algebra in knowledge bases.
Background
Predecessors of ontologies abound. Dictionaries define terms in of other terms and try to be all-encompassing for a language, although the editors may decide to omit specialized words, place names, and the like, to keep the collection manageable. Creating a dictionary is a massive and never-ending effort, subcontracted to a many editors. Formal consistency will not be achieved [BlakeBT:92]. Object-oriented class definitions are another form of ontologies, typically specialized for a narrow domain and a particular set of computations. We observe that object definitions are hierarchically structured, greatly simplifying their management and usability.
Database schemas and their associated entity-relationship models are another representation of ontologies, although typically limited to the abstractions actually represented in the databases. Because databases are processed, mutual consistency does matter. Missing from most schemas are domain definitions or enumerations of the values that identifiers and references can take, although these may be provided as part of the system documentation. Databases built on PASCAL concepts did provide for enumerated datatypes [Schmidt:77]. When autonomously and disjoint are to be combined mediation is needed [Wiedergold:95V]. Since databases are grounded in factual observation, technologies as mediation can resolve differences a posteriori.
The importance of ontologies is recognized in the Artificial Intelligence community [UscholdG:96] and also in the setting of Digital Libraries [HumphreysL:93]. Freestanding ontologies cannot be substantiated by existing observations, but have to deal with hypothetical and future situations as well. When the breadth if coverage is such that committees are needed to define terms, compromises are likely and precision suffers. For search, as in library applications, having imprecision is acceptable when it provides better recall. However, as web-surfers are aware, excessive recall can overwhelm the recipient, and actually make relevant information hard to locate. For computation precision is also valuable, but then alternatives to provide breadth are needed.
The development of adequate ontologies is costly. An ontologist must combine insight and training in the representation technology with a solid domain understanding. Validation of an ontology requires classification of a large and representative set of objects. Processing queries over the objects using the ontology is helpful to discover inconsistencies or ontological errors by comparing the results with the expectation of a domain expert. Terminological inconsistencies are common when sources are distinct [TuttleEa:95]. The ontologist may have to write a lengthy specification if the meaning of a term. A major effort in creating a broads ontology is the CYC project, now with a history of more than 14 years, encompassing a person-century of effort [Lenat:95]. Still, when faced with a new problem, hundreds of new definitions had to be added [Teknowledge:97] and encapsulated into its microtheories to provide disambiguation [LenatG:90]. <<grab one fron Cyc?>>. Even then assignments are open to interpretation. The situations mirrors that of integration of distributed databases, but is raised here to a higher level of abstraction.
When an ontology has been successfully developed in one context it is logical to reuse and extend it, but increasing its breadth will shift the context. The hope is that a domain expert should easily be able to modify ontologies to accommodate new data or scenarios. Tools to keep derived ontologies consistent have been investigated, but not yet found acceptance [OliverSSM:98]. Alternate applications often require alternate ontological structures. Single application ontologies and textbook examples are structured as hierarchies or perhaps as directed acyclic graphs (DAGs). Larger, multi-purpose ontologies tend to become networks, making them much harder to manage, display, and use than hierarchies. All these changes will create new ontologies with alternate structures and overlaps, but also shifted definitions of identically appearing terms.
Much of the focus of ontologists has been on developing larger, static ontologies [Gruber:93], without an explicit contextual constraint, even though most ontology collection is initiated in a specific application domain. There are extensive debates about establishing a single top-level ontological taxonomy underpinning all terms in existence. The expectation is that a comprehensive ontology is reusable and will also force consistency onto the world. However, global agreement is hard to achieve, and even if it is achieved at some instant, its consistency will be transient. Our knowledge, and hence the meaning attached to the terms changes over time. Eventually, the maintenance required to keep the ontology up-to-date will require all resources available for its growth.
John McCarthy, in his related research, handles contexts formally, and represents them as abstract objects [McCarthy:93]. These contexts are mathematical entities used to define situations in which particular assertions are valid. McCarthy's group proposes the use of lifting axioms to state that a proposition or assertion in the context of one knowledge base is valid in another. The lifting axioms can adapt the base rules to another context. The execution of the rules is assumed to be independent of the source domain engines. In practice, a single engine is used.
The CYC use of microtheories bears some resemblance to our definition of contexts. Every microtheory within CYC is a context that makes some simplifying assumptions about the world [Guha:91]. Microtheories in CYC are organized in an inheritance hierarchy whereby everything asserted in the super-microtheory is also true in the microtheory, unless explicitly contradicted. In contrast, we use a much more conservative approach, by using contexts to fully encapsulate an application-specific portion of local source ontologies. Relationships between ontologies are expressed via explicit mapping rules within a context, and no inheritance hierarchy is implied.
Motivation
The SKC approach is motivated to use composition for the inherent scalability and maintainability it supports. We assume that narrow, domain-specific ontologies are internally consistent. Those are maintained by one or few specialists, so that few, if any, compromises arise. If an ontology is used in some computation for a customer, its content and scope has been validated. Such an ontology can be reused either in its narrow domain, or following our model, by new applications if we are able to compose an adequate new context from the existing ontologies using algebraic operations. The ability to compose ontologies reduces the overall cost of building and maintaining an ontology specific to each application.
Inferences in large knowledge bases are known to have poor termination characteristics. Typical workarounds include the imposition of external constraints on the duration and depth of inference,
as provided by defining microtheories in CYC. When using composition, the context of the source domain provide a natural boundary, and our algebra can define new context, enabling a clear ontological structure.
The example introduced in the following section demonstrates the improved reliability achieved as a result of combining information from multiple sources. We also find that the use of problem-specific ontological structures rather than a static global structure results in fewer irrelevant inferences, thus optimizing computational efficiency and improving query reliability.
Using Contexts in SKC
To illustrate our approach we chose real examples and datasets, rather than handcrafted ones. This means we also expose ourselves to the full range of complexities that arise when merging heterogeneous data. We derived the examples here from a set of challenge problems (CPs) put forth in the HPKB. The CPs are questions -- economic, social, political, geographical-- pertaining to crisis management in the Middle East. The query we use as an example is the following:
Which OPEC member nations have also been on the UN Security Council?
Although the question may appear to be simple, arriving at the correct answer turned out to be a non-trivial task. Inconsistencies between the different sources of data as well as errors and irregularities in the data itself were the most significant problems we faced. The data sources we combined were: the on-line text version of the World Factbook for 1996 [CIA:96], the UN policy web site [GPO:97], and the OPEC web [OPEC:97]. In the following discusions, we refer to these data sources as Factbook, UN and OPEC.
Domains
A domain is defined to be a semantically consistent body of information, maintained by a single organization [Wiederhold:95]. The OPEC website is an example of a domain, while the Factbook does not represent a single domain, being an aggregation from multiple sources, and while edited by its publisher, it is not fully consistent.
Domains serve as information sources in our work. We do not expect domains to fully describe their contents, as in some models for information integration [GeneserethSS:94]. We can also not expect them to be error free. A further property of most domains is that we do not control of their contents. By constructing contexts over domains we are able to assert correctness and consistency properties for the relevant information.
Contexts
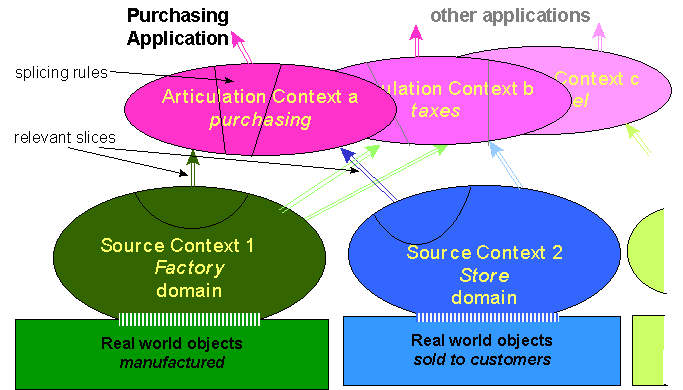
We define contexts to be our unit of encapsulation for well-structured ontologies. Contexts provide guarantees about the knowledge they export, and contain the inferences feasible over them. The basic context, or domain-restricted context encapsulates knowledge pertaining to a single domain. Domain restricted contexts are the primary building blocks which our algebra composes into derived structures. The ontology resulting from the mappings between two source ontologies is assumed to be consistent only within its own context. Such a context is defined to be an articulation context. The articulation context defines an intersection of its sources, and is intended to be modest in size. The articulation, through the articulated concepts in its context, provides access to the full source contexts, although not as an integrated whole, since that could cause errors due to source inconsistencies that have not been articulated.
Interfaces and Rules
In order to better maintain a context's suitability for use or reuse, we specify four interfaces to the context. The interfaces are queryable by the knowledge engineer and are as follows:
Schema Interface provides the knowledge engineers with templates for the kinds of queries that the context guarantees. These templates specify the set of concepts, types and relationships in the context.
Source Interface provides the knowledge engineers with access to the input data sources used to answer the query. This access allows for verification and validation of the knowledge.
.
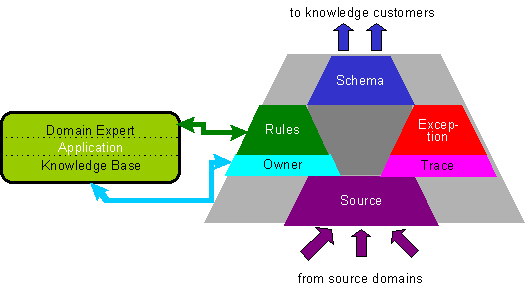
Figure 2: Context Interfaces
Rule Interface defines the rule sets used to transform the data from the sources so they conform to the items in the schema. Each rule contributes a linkage to the knowledge exported by the context. Rules can focus on extraction or on articulation.
Owner Interface contains a time stamp, as well as the names of the context maintainers. Such information is useful for re-use of the context, because it frames its authority, and its validity
The relevance of the interfaces is best understood with an example source context -- ``UN Security Council non-permanent members' years of membership''. The interface components for the source context are as follows, with the caveat that rules are expressed here as pseudo-code:
Schema:
Source:
Rules:
Ownership:
The ruleset above looks for lines with the pattern specifying the membership term in the security council. These lines are then parsed to get the years of the term, and the member nations in those years. The parsing is done by splitting the line based on delimiters and processing the relevant segments. Figure 2 expresses how the interfaces make a context self-describing, by enabling queries over all of its computation and metadata.
Composing Contexts
Algebras offer uniform treatment of their operands, allow their composition, and enable transformations over the resulting expressions. Unfortunately, the operands we wish to manipulate are quite irregular. When there are no constraints on the exceptional instances allowed by a concept, and the concept specification itself is incomplete, it is difficult to imagine an undifferentiated set of operators to compose them. Our algebra has hence to encompass rules that deal with the issue of semantic mismatch.
Semantic Mismatch
In knowledge bases, Frames or Concepts represent a specification of a typed set. This specification is an intensional one, that is, its instances, or extension, do not account for all the possible permutations of its attribute values. For example, our common sense notion of a nation is quite simple: an independent geopolitical region of the globe. However, in the UN security council membership data, the definition of nation also contains a historical component. Yugoslavia is a nation in the UN data, but not in the Factbook. The specification of a concept in knowledge bases is not a legislating one. There are instances that conform to the specification that belong to some other concept. Continuing our example, Switzerland is a nation, but not a UN member nation, therefore not in the UN data.
An intensional specification of a domain is, in general, semantically incomplete. There are often implicit constraints that exclude an instance from the set. If we treat the specification as a test of membership, the excluded instances are false positives. Likewise, there are false negatives, exceptional instances that belong to the set, although they violate the specification. Referring to our example, the Factbook contains an entry for Taiwan, which for political reasons will no longer appear in UN data, although it satisfies intensional rules for being a nation.
Figure 3 below expresses the mismatch in coverage between the concept specification and its extension.

Figure 3: Concept Specification Mismatch
How then can we expect to define an algebra over incomplete specifications and irregular instances? Combining multiple specifications together and merging disparate instances seems fated to produce an increasing divergence between specification and extension. By explicitly considering the class of real-world objects we have a means for assessing this difference, and validating the match obtained of specifications and actual instances [WalkerW:90]. Mismatches can be resolved by extraction and specification rule refinement, including rules to include or exclude single anomalous instances. The problem is compounded by inaccuracy and erroneous information in ontologies and databases. The next subsection provides our framework for using contexts to manage the correspondence.
A Rule-based Algebra
Instead of single operators, we have defined a class of mapping primitives and a class of combination primitives, formed of sequences of simpler operations. Each simple operation is a logical rule, belonging to one of three types. The rules are fired according to structural and lexical properties of the source data, i.e., position and string matching techniques. Note that while the rules effect syntactic changes at the level of bit patterns, the transformations correspond to semantic changes in the concepts and structures of the knowledge sources.
Instance rule: modifies a single item. Rewriting a name to another form, or transforming a type corresponds to such a rule.
Class rule: modifies a class of like organized items. An example is a standardized notation for names of nations wherein all separating spaces and commas are replaced with underscores.
Exception rule: modifies an item or class of items to conform to a specification. Fixing malformed instances and type inconsistencies are actions that fall in this category.
A sequence of these rules, operating over a knowledge source, corresponds to an algebraic operator. The first of these classes is denoted an extraction mapping and the second class is that of articulation mappings.
Extraction Mappings
We need a mechanism to initially construct contexts from knowledge sources domains. The class of extraction maps provides the primitive for creation of domain restricted contexts. First we perform any necessary restructuring to bring the data into an internal format. We follow this extraction with a refinement step that fixes spelling errors, adds underscores to names where necessary, etc.
To illustrate the usage of extraction mappings we return to our example. Initially, we observed that the Factbook contained a heading for membership in international organizations, without specifically noticing UN security council membership information. Our first context consisted of a relation mapping country names to international organizations of which they were members. We created a second context to include historical security council data from the UN data set, a relation mapping country names to their years of membership in the security council.
Articulation Mappings
In SKC multiple sources are combined using articulation mappings to create articulation contexts, as sketched in Figure 4. Articulation mappings, provided by application experts, further improve the concordance between specification and extension, because errors present in single sources can be corrected. In general, the application expert will choose a mapping on the basis of expertise provided by one of the sources. Again the running example illustrates some mapping problems we encountered while attempting to utilize heterogeneous data from different sources.
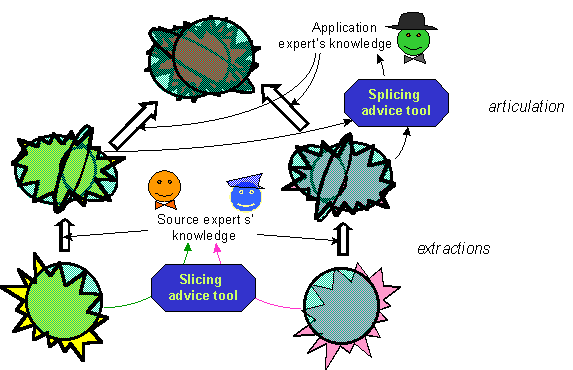
Figure 4: Extractions’ and Articulation Mappings
Our first CP application query
Which OPEC member nations have also been on the UN Security Council?
required a mapping of country names between the Factbook and UN contexts. We mapped Gambia to The Gambia, and chose a null mapping for Yugoslavia. Other queries such as ``Name the country which contains the site of the 1984 Winter Olympics'', require a context that maps Yugoslavia to the nations that resulted from its breakup, in order to correctly answer Croatia. These examples show that in general there is no static mapping of multiple concept instances that is universally valid.
Using the Factbook context alone gives us the wrong answer: Gabon. While verifying the latest year an OPEC member was in the security council in the OPEC context we retrieved the instance data Gabon 1999. The Factbook lists Gabon as an OPEC member, and the UN data contains security council membership information through 1999, since membership is determined in advance. However, when verifying OPEC membership at the source, we find that Gabon left OPEC in 1994. We extracted an OPEC membership context, a relation that contains member countries with years of membership, and extended the query context to explicitly prioritize the OPEC context over the Factbook's OPEC membership data.
A repeat of the previous query on the articulated context returned the correct answer: Indonesia in 1996. At this time a complete re-examination of the data sets revealed that the Factbook's UN membership attribute contains observer nations as well as security council membership, although two years out of date. Such expertise is rarely explicitly exported as metadata, but will be known to regular consumers of the source information – in our model the articulation expert.,
In retrospect, the Factbook purported to contain sufficient information to answer the query, but, since it is an aggregation of multiple sources, contains inconsistencies on content and time-of-validity. Although it is updated annually, its size makes maintenance hard. Primary sources, as, OPEC and the UN have much more at stake in maintaining up-to-date membership information for their own organization, and will be responsive to correcting errors that their members notice. Few organizations or foreign countries will complain to the CIA regarding errors about them.
Source Prioritization and Correctness
By using rules to explicitly state the experts’ preferences with regard to source accuracy, and completeness, our approach avoids the pitfalls of using a fixed heuristic to determine the choice of source data. The previous example illustrates the importance of source accuracy. The use of domain restricted sources with up to date and accurate information, compensate for deficiencies in broader, aggregated sources.
Figure 5 illustrates that the conjunctive model, used in database joins, which reject all items absent from a source, is overly restrictive. Likewise, a disjunctive model, used in knowledge aggregation, that accepts any item which appears in any source keeps too many source instances. When we handled queries about membership in the UN general assembly, we built a table of country names that were used differently in the Factbook and the UN pages. We included about twenty rules specifically enumerated to deal with different naming conventions.

Figure 5: Lexically Driven Mappings are Inadequate
The definitions we have used are convenient, but they do not appear, at first glance, to have a firm grounding. Category theory [Pierce:91] provides a foundation for discussing algebras and their properties, but their objects are completely defined abstract entities, while our approach also can use validation by reference to the real-world, an to the ontologies that represent the real world . [JanninkSVW:98] explores a theoretical basis for our framework.
Operators
Extraction mapping defines members of the source context by translation of a slice of the source context. An example of translation is a retrieval of OPEC member nations and their years of membership from the organization's web site. Extraction for articulation focuses on semantically similar information, and supporting terms. Translation is related to McCarthy's lifting axioms [McCarthyB:94], [BuvacM:98]. In SKC, after translation the results may be spliced into a conceptual intersection by a combination operator.
Both of these operators require rules, since we do not assume that just because terms are spelled similarly that the objects they refer to will match. A rule that
A.country = B.country may be adequate, but most rules will be more complex, as A.GNP = B.GDP + B.Exports - B.Imports.The intersection is the context which is a specified extension of the source contexts' definitions. The intersection varies with the definition of the source interface of the context.
Algebraic criteria
We are still in process of developing the operators to satisfy algebraic properties of sound composability. The criteria include that the operations can be rearranged, so that alternate compositions can be evaluated.
To the extent that this is achieved, optimization of execution will be enabled and the record of past operations can be kept and reused. Figure 6 illustrates our vision. We also expect to need a difference operator to compute the extent of relevant local subsets and their locally independent complements.
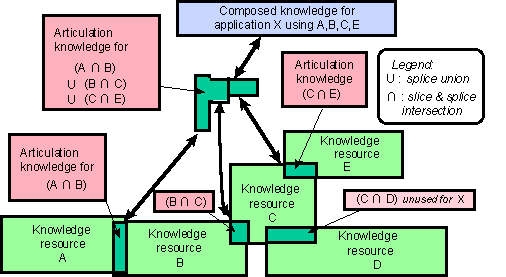
Figure 6: Vision for Multi-level Composition.
Tools
A product of our ongoing research is to develop tools that will aid the expert is discovering and formulating rules, is indicated in Figure 4. Tools to aid in extraction may access referenced abstract or real objects to validate matches. Checking the names and counts of object instances can help in gaining an understanding of concept semantics. Tools to aid integration can use simple word matching for suggestions, but may also use thesauri, as the Knowledge Source Server tool for clinical data [McCrayEa:96] and related products [TuttleCSN:95]. Correctness of matches can be validated by going back to the extraction phased and checking of the cardinalities of the subsumed concepts match.
We envisage that feedback and interaction among the participants will be needed to set up initial articulation contexts that can serve useful applications. Once the processes are established, the operators and their rules will form an executable documentation allowing reuse of the process, and effective maintenance as source ontologies evolve or application demands change. We observed that to develop the integrated ontology for the current HPKB project required much adaptation, reconciliation, and alignment of the existing ontological sources [ChalupskyHR:97]. Since the alterations were performed on local copies on as-needed basis, subsequent maintenance or reintegration will require substantial ongoing efforts. Assignment of responsibilities to experts’ roles in our model also helps in long-term ontology management, and reduces the dependence on an informal corporate memory.
Knowledge Base Role
In the previous sections, we have defined context as the unit of encapsulation for ontologies, and an algebra to serve as constructors and composition operators for contexts. Our examples motivate the use of the algebra to aid in answering application-specific queries, for improving accuracy, simplifying maintenance, and creating new concepts from existing data. In this section we examine the role of contexts within knowledge base systems with an eye towards their practical benefits.
Knowledge Base Efficiency and Performance
We perform single-pass preprocessing of sources on demand to maximize efficiency. This restriction limits the degree of nesting of contexts from a source to any particular query context. We are using an OKBC [ChaudhriEa:98] interface to assert the results of our computations to a knowledge base. We limit extraction for context creation to the concepts which are relevant to the contexts and their articulation. Thus, we restrict the amount of inference we allow to achieve an answer at this stage. These concepts will be adequate to decompose queries. Our intent is that the subqueries created by top-down decomposition will be transmitted to the sources, where source-specific inferencing can take place, using terms and relationships that have not been lifted into the derived contexts.
Encapsulation of contexts and sources, with sparse interfaces, allows knowledge bases with differing knowledge representation to interoperate. In particular, the representation in a knowledge base is structurally and semantically optimized for its own inference engine. Features that go beyond a common first-order subset tend to differ [CutkoskyEa:93]. Porting a different representation to another inference engine will not, in general, result in equivalent inferencing performance. Encapsulating multiple knowledge base inferences and combining them through the algebra ensures that inferences occur where they will be most efficiently performed.
Ontology Structure and Maintenance
A crucial aspect of ontology maintenance is its clarity of structure. Knowledge engineers must comprehend the shape of the ontology and its relationships in order to accurately gauge how changes will affect the knowledge base's performance. At a recent workshop, a presentation [ChalupskyHR:97] described preliminary efforts to align and merge two ontologies containing over 3000 concepts apiece. From an observers perspective it became evident that the original structure of the ontology was fragile enough that no substantial transformation or enhancement was feasible. Many current approaches envisage much larger ontologies [FikesF:98].
Adding encapsulation and composition to knowledge bases benefits ontology maintenance as well. Ontologies may be decomposed into application-specific units that are reused only as necessary.
Maintenance taking place within context boundaries will not affect performance of external components, as long as the context interfaces are maintained. A planned SKC operator: difference, will identify parts of ontologies not used in slices used for articulations.
A dual structure emerges from the SKC architecture: first, a collection of traditional relatively static, locally maintained ontologies, and, second, an dynamic structure based on contexts related by application-driven composition. Since composition is an inherently dynamic operation, the context structure is open-ended and evolves as requirements change. The resulting ontology has a cleaner structure, since relationships defined by concepts' functional roles in diverse applications are no longer shoehorned into the ontology alongside local inheritance and instance relationships.
Conclusion
We do not subscribe to the notion that one ontology can serve all objectives, rather we adopt an approach to ontology design and development by selection through slicing of sources and algebraic composition of their intersections. We expect that this approach will reduce the tensions between knowledge base builder and the applications or knowledge customers that use the knowledge base. To do so, we provide domain experts with a practical methodology for engineering application-specific ontologies which simplify the task of maintaining the knowledge. We expect that the effort required to craft a new application context by composition is less than the effort experienced when a massive knowledge base has to be augmented for a new application.
We have introduced a new formalism for context in knowledge bases, that enables localized and controlled inferences, resulting in efficient processing of queries. We use a constructive and scalable mechanism in the form of a rule-based algebra, which enables the composition of an open-ended taxonomy of new relationships between contexts. Our method reduces some of the ontological semantics to a syntactic structure. We plan to perform deep query inferences within their source context, using the source engines, in order to preserve fidelity to the intents of their creators.
Together, encapsulation and composition enable application-specific optimizations. Using delimited contexts throughout will achieve greater accuracy. In the search for more systematic notions of ontology, the context algebra provides a novel and complementary technique. The algebraic expressions describing the composition can be reused, and also document the path back from the application to the sources for justification of inferences made and for further information retrieval from the sources and their attached systems.
Acknowledgements
This research is being supported by a grant from the Air Force Office of Scientific Research (AFOSR) as part of its New World Vistas program, and executed in cooperation with DARPA’s HPKB program. Srinivasan Pichai and Danladi Verheijen have made substantial contributions to this research. We appreciate programming support provided by Neetha Ratakonda. David Maluf participated in prior research on this topic and continues to provide feedback [MalufW:97]. Thanks also to Rudi Studer, Erich Neuhold, and R.V. Guha for their helpful comments and feedback.
References
.
[BlakeBT:92] G.E.Blake, T.Bray, and Frank W.Tompa, ``Shortening the OED: Experience with a Grammar-Defined Database''; ACM Trans. Information Systems Vol. 10 No. 3, July 1992, pp. 213-232.
[BuvacM:98] Sasa Buvac and John McCarthy: Combining Planning Contexts; Stanford University, Formal AI group, 1998, http://www-formal.stanford.edu
[CIA:97] Central Intelligence Agency: CIA Factbook; 1997, http://www.odci.gov/cia.
[ChalupskyHR:97] H. Chalupsky, E. Hovy, and T. Russ, T.: Presentation on Ontology Alignment; NCITS.TC.T2 ANSI at ad hoc group on ontology, 1997.
[ChaudhriEa:98] Vinay K. Chaudhri, A. Farquhar, R. Fikes, P.D. Karp, and J.~P. Rice, Open Knowledge Base Connectivity (OKBC) 2.0.3; Draft standard proposal, SRI International, July 1998.
[CutkoskyEa:93] M.Cutkosky, R.S. Engelmore, R. Fikes, M.R. Genesereth, T.R. Gruber, W.S. Mark, J.M. Tenenbaum, and J.C. Weber: "PACT: An Experimental in Integrating Engineering Systems"; IEEE Computer, vol.26 No.1, 1993, pp. 28-37.
[FikesF:97] Richard Fikes and Adam Farquar: Large-Scale Repositories of Highly Expressive Reusable Knowledge; Stanford KSL report 97-02, April 1997.
[GeneserethF:92] M.Genesereth and R. Fikes: Knowledge Interchange Format (KIF); Reference Manual, Stanford University CSD, 1992, Updated 1996, http://logic.stanford.edu/kif/.
[GeneserethSS:94] Michael R. Genesereth, Narinder P. Singh and Mustafa A. Syed: ``A Distributed and Anonymous Knowledge Sharing Approach to Software Interoperation"; Proc. Int.Symp. on Fifth Generation Comp Systems, ICOT, Tokyo, Japan, Vol.W3, Dec.1994, pp.125-139.
[GPO:97] Global Policy Organization: UN Global Policy Site; 1997, http://www.globalpolicy.org.
[Gruber:93] Thomas R. Gruber: ``A Translation Approach to Portable Ontology Specifications''; Knowledge Acquisition, Vol.5 No. 2, pp.199-220, 1993.
[Guarino:97] Nicola Guarino: Presentation on Formal Ontologies; NCITS.TC.T2 ANSI ad hoc group on Ontology; 1997.
[Guha:91] R.V. Guha: Contexts: A formalization and some application; Doctoral dissertation, Stanford University. Also MCC Technical Report Number [ACT-CYC}-423-91, 1991.
[HumphreysL:93] Betsy Humphreys and Don Lindberg: The UMLS project : Making the conceptual connection between users and the information they need; Bulletin of the Medical Library Association, 1993, see also http://www.lexical.com.
[JanninkSVW:98] Jan Jannink, Pichai Srinivasan, Danladi Verheijen, and Gio Wiederhold: "Encapsulation and Composition of Ontologies"; Proc. AAAI Summer Conf., Madison WI, AAAI, July 1998.
[KashyapS:96] V.Kashyap and A. Sheth: Semantic and Schematic Similarities between Database Objects: A Context-based Approach; VLDB Journal, 1996, Vol. 5 No.4 pp.:276--304.
[LenatG:90] Douglas Lenat and R.V. Guha: Building Large Knowledge-Based Systems; Addison-Wesley, 1990.
[Lenat:95] Douglas B. Lenat "CYC: A Large-Scale Investment in Knowledge Infrastructure"; Comm. ACM, Vol.38 No.11, Nov. 1995, pp.33- 38.
[MalufW:97] David A. Maluf and Wiederhold Gio: "Abstraction of Representation for Interoperation"; Tenth International Symposium on Methodologies for Intelligent Systems, Lecture Notes in Computer Science, Springer Verlag, pp 441-455, Oct., 1997.
[McCarthy:93] John McCarthy: "Notes on formalizing context"; Proceedings of the Thirteenth International Joint Conference on Artificial Intelligence; AAAI 1993.
[McCarthyB:94] John McCarthy and Sasa Buvac: "Formalizing Contexts (Expanded Notes)"; in Aliseda, vanGlabbeck, Westerstahl: Computing Natural Language, 1997; Stanford University, Formal AI group, Technical Note Stan-CS-TN-94-13, 1994, see http://www-formal.stanford.edu.
[McCrayEa:96] Alexa T. McCray, AM Razi, AK Bangalore, AC Browne, and PZ Stavri: "The UMLS Knowledge Source Server: A Versatile Internet-based Research Tool"; Proc AMIA Fall Symp., 1996 pp.164-168.
[OliverSSM:98] Diane E. Oliver, Y. Shahar, E.H. Shortliffe, M.A. Musen: Representation of Change on Controlled Medical Terminologies"; Proc. AMIA Conference, Oct.1998.
[OPEC:97] Org. Petroleum Exporting Countries: OPEC web site; Org. Petroleum Exporting Countries 1997, http://www.opec.org.
[Pierce:91] B.C. Pierce: Basic Category Theory for Computer Scientists; The MIT Press, 1991.
[RoyH:97] N.~F. Roy and C.~D. Hafner: The State of the Art in Ontology Design; AI Magazine, 1997, Vol.18 No.3, pp.53--74.
[Schmidt:77] J.W. Schmidt: "Some High Level Language Constructs for Data of Type Relation"; ACM Transactions on Database Systems , Sep.1977, Vol.2 No.3, pp.247-261
[SchuylerHTS:93] PL Schuyler, WT Hole, MS Tuttle, and DD Sherertz: "The UMLS Metathesaurus: Representing Different Views of Biomedical Concepts": Bull Med Libr Assoc., April1993; Vol.81 no.2, pp217-222.
[Sowa:98] John F. Sowa: Knowledge Representation Logical, Philosophical and Computational Foundations; PWS Publishing Company, 1998.
[Teknowledge:97] Teknowledge: High-Performance Knowledge-Bases (HPKB); maintained by Teknowledge Corp. for the Defense Advanced Research Projects Agency, 1997, http://www.teknowledge.com/HPKB.
[TuttleCSN:95] Mark S.Tuttle, S.Cole, D.D. Sheretz, and S.J. Nelson: "Navigating to Knowledge"; Methods of Information in Medicine, vol.34, No.1-2, 1995, pp. 214-231; http://www.lxt.com.
[TuttleEa:95] Mark S. Tuttle, ON Suarez-Munist, NE Olson, DD Sherertz, WD Sperzel, MS Erlbaum, LF Fuller, WT Hole, SJ Nelson, WG Cole, et al.: "Merging Terminologies"; Medinfo 1995; Vol.8 (Pt 1) pp.162-166.
[UscholdG:96] Mike Uschold and Michael Gruninger: "Ontologies: Principles, Methods, and Applications"; Knowledge Engineering Review, Nov. 1996.
[WalkerW:90] Michael G . Walker and Gio Wiederhold: "Acquisition and Validation of Knowledge from Data"; in Z.W. Ras and M. Zemankova: Intelligent Systems, State of the Art and Future Directions, Ellis Horwood, 1990, pages 415-428.
[Wiederhold:94] Gio Wiederhold: "An algebra for ontology composition"; in Proceedings of 1994 Monterey Workshop on Formal Methods; U.S. Naval Postgraduate School, 1994, pp. 56--61.
[Wiederhold:95] Gio Wiederhold: Objects and Domains for Managing Medical Knowledge; Methods of Information in Medicine, Schattauer Verlag, 1995, pp. 1--7.
[Wiederhold:95V] Gio Wiederhold: ``Value-added Mediation in Large-Scale Information Systems''; in Meersman(ed): `Database Application Sematics', Chapman and Hall.
[WiederholdG:97] Gio Wiederhold and Michael Genesereth: "The Conceptual Basis for Mediation Services"; IEEE Expert, Vol.12 no.5, Sep.-Oct.1997, pp. 38-47.
======================== o =======================